

概要
車のモデルの本質を、顧客のレビューから導き出された単一のベクトルで要約したいと思ったことはありますか?このブログでは、テキストの要約にOpenAIのText-Davinci-003、埋め込み生成にはSonoisa SBERTを活用した、テキスト分析のユニークな応用例について掘り下げています。
この先進的なモデルがどのように連携して、車のモデルに対して単一のベクトルを生成するのかを比較します。また、最良の結果を示すだけでなく、ベクトルに基づいて車のモデルをインタラクティブに検索できるようにもしています。それらはすべて、私たちのデモサイトで簡単に検索することができます。
1. はじめに
今日の情報豊富な時代において、車のレビューは潜在的な購入者とメーカーの両方にとって欠かせないツールです。それらは、実際のユーザーからのパフォーマンス、信頼性、全体的な満足度に対する深い洞察を提供します。しかし、これらのテキストが豊富な評価から意味のある、そして実用的な特徴を抽出するのは困難な作業です。
主な課題は、レビューの量と多様性に起因しています。それらは専門家の分析、個人の話、多様な視点を総合しており、それぞれが独自の価値を持っています。さらに、これらの評価を量的な指標や特徴に変換して検索機能を強化するのは複雑なプロセスです。これに、日本語のニュアンスを理解する層を加えると、特に多くの分析モデルが主に英語向けに作られている場合、その複雑性はさらに増します。
私たちのミッションは明確でありながらも野心的です:これらの日本語のレビューに内在する豊かな情報を活用し、車の検索機能を強化することです。ユーザーが自分のニーズを表現し、それに応じて自分の仕様にシームレスに合致する車の提案を受け取るというシステムを構想しています。このビジョンを実現するには、単なるキーワードを超えて、これらのレビューの感情や文脈を深く理解することが不可欠です。
この課題に取り組む過程を一緒に探究しましょう。日本語のユーザーレビューを、充実した車の検索体験のための強力なツールに変えるさまざまな方法を探っていきます。
2. 情報検索におけるテキスト分析の背景
テキスト分析、特に検索の領域においては、技術の急速な進展に伴い大きく進化しています。ここでは、テキストを数値ベクトルに変換することが検索機能をどのように改善するのか、そして特に車のレビューがこのプロセスにおいてなぜ重要なのかを探究します。
2.1 テキストを数値ベクトルに変換するということ
基本的に、テキストをベクトルに変換するプロセスとは、人間の言語とその複雑性を、機械が効率的に処理できる形式に変換することです。この変換によって、アルゴリズムはテキスト情報をより構造化された方法で「理解」および「解釈」することができ、高度な分析と検索機能を容易にします。特に検索機能において、テキスト情報を数値ベクトルに変換することは不可欠です。これらのベクトルは、テキストの内容と感情の「指紋」のようなものとして機能し、情報の本質を捉えます。
例えば、車のレビューでの「powerful engine(強力なエンジン)」というフレーズは、ベクトル[0.7, 0.9, -0.2,...]に変換されるかもしれません。各数値は、フレーズの特定の言語的または意味的な側面を表しています。
2.2 車のレビューの重要性
- 情報の宝庫:車のレビューは、潜在的な購入者とメーカーの双方にとって、多角的な洞察の中心となっています。それらは、車の性能、信頼性、全体的なユーザー満足度について包括的な理解を提供します。
- 専門家と一般ユーザーの視点:専門家の批評と一般ユーザーのフィードバックが結合して、車の長所と改善の余地についてより完全なイメージを描き出します。
- 魅力に焦点を当てる:レビューは、特定の車が異なるユーザー層に対して他の車よりも魅力的である理由となる、しばしば抽象的な特性を明らかにします。
2.3 セマンティック検索
- キーワードを超えて:キーワードベースの検索の限界が次第に明らかになってきました。セマンティック検索はさらに深く探り、クエリー背後の完全な意味を理解することを目指します。
- セマンティクスの理解:これは、何が言われているかだけでなく、どのようにして、なぜ言われているかについてもです。意味と文脈に深くダイビングすることで、セマンティック検索はユーザーエクスペリエンスを新たな高みに引き上げます。
- NLPの活用:高度な自然言語処理技術、特にトランスフォーマーモデルが、セマンティック検索を現実のものにするための要となっています。
- 関連性と共鳴:この新しいパラダイムにおいて、検索結果は単語の単なる出現によってではなく、そのセマンティックな関連性と文脈的な整合性によってランク付けされます。
- 益々の利点:
- 精度と体験:検索がより正確であり、ユーザーは求めているものをより簡単かつ迅速に見つけます。
- 曖昧なクエリの解読:曖昧または複雑な検索用語を解釈する能力。
- 意図の理解:単語を超えて、システムはクエリー背後の意図を把握し、結果をユーザーの期待により近づけます。
2.4 現実世界のアプリケーション
今日の主要な検索エンジンのアルゴリズムを駆動させることから、推薦システムを洗練すること、知識管理プロセスを効率化することまで、セマンティック検索の応用は多岐にわたり、広範に及びます。その影響は、技術が進展し続けるにつれて拡大すると約束されており、私たちが情報にアクセスし処理する方法において、変革的な時代が始まる兆しを見せています。
3. 技術要素
3.1 Sentence-BERT (Sonoisa Model) - 効率的な文埋め込み
- Sentence-BERT の役割と効率性: 自然言語処理の領域は、BERT(Bidirectional Encoder Representations from Transformers)の登場によって革命を遂げました。しかし、文の埋め込みを必要とするタスクにそれを適応させるには、より最適化されたモデルが求められました。ここでSentence-BERT(SBERT)が登場します。ReimersとGurevychによって2019年に導入されたSBERTは、特に文レベルの埋め込みを生成するためにBERTモデルを修正したものです。BERTがトークンレベルの埋め込みを生成するのに対し、SBERTはプロセスを効率化し、文に特化したより高速で効率的な出力を提供します。日本語テキストに関連する特定のアプリケーションにおいては、私たちはその言語に特化して微調整されたSonoisaモデル -
sonoisa/sentence-bert-base-ja-mean-tokens-v2- を使用しています。
モデルについて: Sonoisaモデルは、日本語テキストに特化して設計されたSentence-BERTの適応版です。以下にその仕様を示します:
- モデル名:sonoisa/sentence-bert-base-ja-mean-tokens-v2
- 最大シーケンス長:512トークン。これは、ほとんどの文や段落に十分です。
- 出力次元:768、多くの現代のNLPモデルの出力サイズに合わせています。
- 適切なスコア関数:コサイン類似度。密なベクトル空間でのセマンティックな類似性を測定するのに理想的です。
- サイズ:443MB。その機能を考慮すると、妥当にコンパクトです。
- 起源:このモデルはゼロから作られているわけではありません。代わりに、cl-tohoku/bert-base-japanese-whole-word-maskingから微調整されています。
独自の特長とBERTに対する優位性:元のBERTは非常に多機能ですが、固定サイズの文の埋め込みを生成する際には、SBERTが最適です。後者はシャムネットワークまたは三重ネットワークの構造を使用してこれを実現します。トークンごとに作業するのではなく、一度に全文の埋め込みを生成するように微調整されており、文間のセマンティックな類似性の比較のようなタスクでかなり速く、より適任です。
応用:SBERTの有用性は、速度と効率だけに限られません。その機能は、意味に基づいてコンテンツをマッチさせることが目的であるセマンティック検索で広く認識されています。クラスタリングのアプリケーションも非常に恩恵を受けます、なぜならセマンティックな内容に基づいたグループ化がより正確になるからです。私たちのプロジェクトでは、Sonoisaモデルが中心的な役割を果たしており、生のレビュー、連結されたレビュー、または生成された要約のテキストを効率的なテキスト埋め込みにエンコードします。
3.2 テキストのトークン化
重要性と意義:テキストがSBERTやDavinci Text 3のようなモデルに処理される前に、トークン化と呼ばれる重要なステップを経なければなりません。本質的に、トークン化は生のテキストをトークンと呼ばれる小さな単位に分解します。これらのトークンは、単語、フレーズ、または記号であり、機械学習モデルが解釈する基本的な構成要素です。
SonoisaとText-Davinci-003のためのテキストの準備: トークン化プロセスは、モデルとそのアクセス方法によって異なります。Sonoisaの場合、目的はテキストをモデルの埋め込みプロセスと互換性のある方法でセグメント化することです。一貫した正確なパフォーマンスを確保するために、Sonoisaモデルの訓練に使用された同じトークナイザを使用することが不可欠です。
Text-Davinci-003の場合、OpenAIのAPI経由でアクセスされた場合、ユーザー側での事前トークン化は必要ありません。APIは、生のテキストを処理し、モデルの処理のためにそれを準備するように設計されています。
- 例:テキスト「The quick brown fox jumped over the lazy dog.」を考慮してみましょう。トークン化の後、この文を個々の単語またはさらに小さな単位のシーケンスとして表現することができます。より高度な設定では、これらの単語はさらにユニークな整数にマッピングされ、以下のようなものが生成されます: [101, 1996, 4248, 2829, 4415, 1999, 1996, 13336, 2163, 1012, 102].
3.3 K平均法クラスタリング - 類似のものをグループ化
導入と利点:K平均法クラスタリングは、データを独立した、非重複のクラスタに分けるために設計された教師なし機械学習の手法です。クラスタ内の分散(しばしば慣性とも呼ばれる)を最小限に抑えることで、K平均法はクラスタ内のデータができるだけ類似しているようにします。この類似したデータ片をグループ化する能力により、K平均法は構造化されたカテゴリー分けが鍵となるシナリオで非常に貴重です。
プロジェクトの文脈での適用:私たちの車のレビュー分析の範囲では、K平均法はセマンティックな内容に基づいてレビューをグループ化するという極めて重要な役割を果たしています。これによって、パターンを識別し、代表的なレビューを抽出し、その結果、後続の分析ステップの効果を高めることができます。それがSBERTでのエンコーディングであれ、OpenAIのDavinciモデルでの要約であれ、その効果は高まります。
4. ケーススタディ:日本語の車のレビュー
4.1 データソース
このケーススタディで使用された車のレビューは、著名な日本の中古車ウェブサイトから取得されました。このプラットフォームは、自動車愛好者や潜在的な購入者の間で高く評価されており、特に中古市場におけるさまざまな車種についての洞察を提供しています。このサイトからのレビューは、経験豊富な車のユーザーからの洞察を組み合わせており、さまざまな車種を所有する際の喜びと困難の両方を捉えています。
4.2 目的
- レビューからベクトルへ:全体的な目標は、これらの複雑なレビューから車のベクトル表現を抽出する効果的な方法を設計することです。
- Solrとの統合による密ベクトル検索:人気のある検索プラットフォームであるSolrが、これらのベクトルを格納するために活用されます。これらの車のベクトルをインデックス化することで、「密なベクトル検索」と呼ばれる機能を有効にします。この高度な検索機能は、結果が単なる表面的なテキストの一致に基づくものでなく、ユーザーのクエリとのより深い、セマンティックな整合性を確保することになります。
- 検索の再定義:ユーザーがニュアンスと文脈に富んだ日本語、特に自然なテキストクエリを使用して検索を実行できるようにすることを目指しています。ユーザーが自然な日本語のテキストで検索を行うことができるようにし、ユーザーの意図と検索結果とのギャップを埋めることを望んでいます。たとえば:
- 例1: 家族でキャンプや買い物に行ける車
- 例2: 通勤途中に子供を学校に送れる車
4.3 ディレクトリ構造
レビューをクロールした後、データは効率的な分析を容易にするために体系的に整理されました。以下は、レビューを保存するために使用されたディレクトリ構造の一例です:

各ブランドには専用のフォルダがあり、さらに個々のモデルのフォルダに分かれています。それぞれのモデルのフォルダ内には、対応するレビューが格納されています。
4.4 ユーザーレビューの例
私たちが取り扱っているデータの具体的な感じを提供するために、典型的な車のレビューを表すJSONのスニペットを以下に示します:
{
"title": "ワイルド",
"maker": "レクサス",
"model": "CT",
"eval_text": "【総合評価】 とてもいいと思います! 【良い点】 色がかっこいし綺麗にみえる 【悪い点】 じぶんてきにはおおきさがもっとコンパクトになってほしい",
"eval_comprehensive": " とてもいいと思います! ",
"eval_dislike": " じぶんてきにはおおきさがもっとコンパクトになってほしい",
"eval_like": " 色がかっこいし綺麗にみえる "
}
4.5 データの統計情報
データの統計情報は以下の通り。:
- ブランド数:85
- モデル数:1,371
- レビューの総数:68,441
- 注意:これらの数字を集計する際に、レビューが一切ない車のモデルは考慮から外れています。これは、分析が実質的なデータに基づいていることを確保するためです。
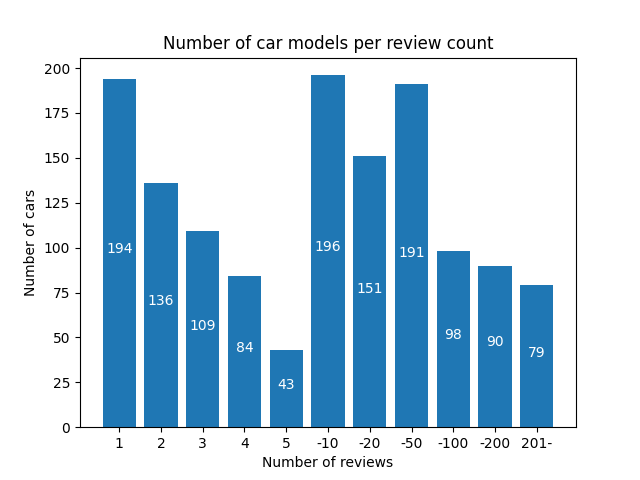
視覚的な表現 – データセットの分布を覗いてみる:
以下の図は、各レビュー件数の範囲に該当する車の数をグラフィカルに表示しています。これにより、特定のレビュー件数の範囲を受けた車のモデルがいくつか、どの程度広くレビューされているモデルがあるのか、または最小限のフィードバックしか得られていないモデルがいくつか、がわかります。
5. 方法その1: 車のレビューベクトルの平均
手法に深く掘り下げると、私たちの最初のアプローチはかなり直感的な概念、すなわち平均値を取ることに依存しています。ユーザーレビューの文脈では、これは複数の感情と意見を単一のベクトル表現に凝縮するという作業になります。
5.1 定義
この方法の要点は、テキストデータの塊を数値ベクトルに変換することにあります。これらのベクトルは、テキストの核心的な感情と意味を凝縮した形です。平均値を取るというのは、特定の車モデルに関連する一連のレビューに対して、これらのベクトルの平均を取ることを意味します。
5.2 手続き

Sentence-BERTモデル:各レビューに対して、テキストはまずトークン化され、次にSonoisa Sentence-BERTモデルを通して処理されます。出力は768次元の固定サイズのベクトルです。このモデルは、最大シーケンス長512トークンを処理できる能力があり、スコアリング関数としてコサイン類似度を使用していることにも言及する価値があります。
ベクトルの平均化:各レビューがSBERTを用いてベクトルにエンコードされた後、次のステップは集約です。各車モデルに対して、その関連するすべてのレビューからベクトルが平均化されます。この平均ベクトルは、問題の車モデルに対する集合的なセンチメントを表すものとされています。
5.3 例
特定の車モデルに対する3つのレビューがあると想像してみてください。
- 「燃費は素晴らしいが、デザインは地味。」
- 「手頃な価格で効率的だが、あまりおしゃれではない。」
- 「日常の通勤には経済的な選択だが、見た目は得意ではない。」
Sentence-BERTモデルは、これらの各レビューを個々のベクトルに変換します。次に、平均化処理を行い、これらのベクトルを1つのベクトル表現にまとめます。この結果、この車モデルに対する燃費の良さと、それに対照的なやや物足りないデザインという、反復するテーマ性が際立つようになります。
5.4 課題と考察
表面上は、平均を取る方法は複数のレビューをまとめる効果的な手段に見えますが、欠点もあります。特に多様な意見が寄せられた場合、平均を取ることで対照的な見解が希薄になる可能性があります。
この方法の顕著な落とし穴は、区別がぼやけるリスクがあることです。例えば、レビューの半分が車のデザインを称賛し、残りの半分がそれを批判している場合、平均値は中立を示すかもしれません。このような場合、重要な洞察が隠される可能性があり、結果として誤解を招く可能性があります。
この方法は直訳的ですが、より複雑な手法へと進むにあたって基礎的な理解を提供します。これらの方法を経て、特に多様な車のレビューの文脈において、テキスト分析の層の厚さが強調されます。
6. 方法その2: K平均法クラスタリングとSBERTモデルエンコーディング
私たちが意味のある車の表現を導き出すという探求が続く中で、平均を取る方法によって生じる課題を回避しつつ、レビューの多様性を包括するという約束を持つクラスタリングの領域に足を踏み入れました。
6.1 定義
データ分析においてクラスタリングとは、類似性に基づいてデータポイントをグループ化するプロセスです。私たちの車のレビューにおいては、特定の車モデルに対する類似の感想を伝えるレビューをまとめることを意味します。大量のレビューに対処する際に特に重要となるのは、フィードバックの本質を希釈することなくコンパクトな表現を提供することです。
6.2 手続き

トークン数の制限と戦略
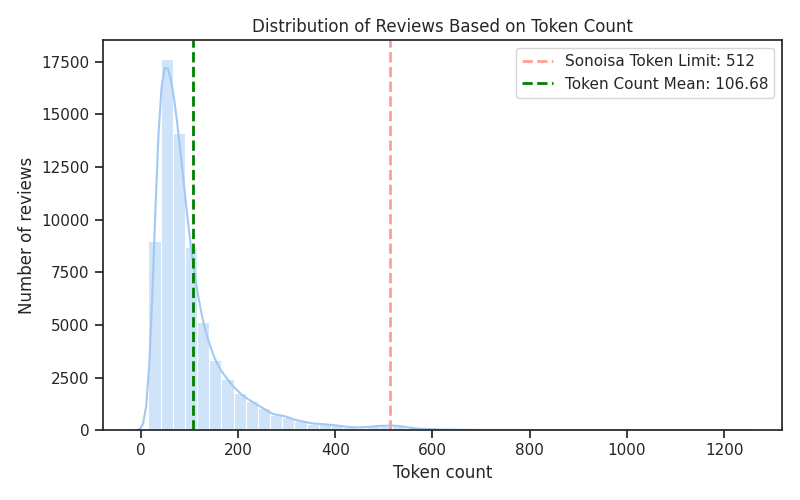
私たちが使用しているSonoisa Sentence-BERTモデルは、各入力に対して最大512トークンの制限があります。平均レビューが106.68トークンを含むことを考慮すると、この制限を超えないように情報を最大化する戦略を慎重に選ぶ必要がありました。
クラスタ数の選択: k の役割
このトークン制限内で効果的な表現を確保するために、私たちはK平均法アルゴリズムにおける最適なクラスタ数kを分析しました。この決定は、経験的な分析に基づいています:
k の値 |
レビュー毎のトークン数上限 | トークン数制限下でのレビュー割合 |
|---|---|---|
| 2 | 256 | 93.77% |
| 3 | 170 | 85.39% |
| 4 | 128 | 76.49% |
慎重な検討の結果、 k = 3 が選ばれました。これにより、レビューごとのトークン制限は170となり、レビューの85.39%をキャプチャすることができます。 k = 2 および k = 4 も検討されましたが、それぞれ表現の多様性が制限されるか、または多くのレビューを収容できないという問題がありました。
K平均法クラスタリングとエンコーディング
K平均法クラスタリングは、レビューをそのセマンティックな内容に基づいてグループ化するために使用されます。この内容はエンコードされたベクトルを通じて表現されます。クラスタが形成されたら、各クラスタの中心に最も近いレビューを最も代表的なものとして選びます。この「中心レビュー」の集合は連結され、その後Sentence-BERTを用いて各車モデルのための統一されたベクトルを生成します。
6.3 例
このプロセスを車に関するシナリオで具体的に理解しましょう。車の愛好者がお気に入りの車モデルについて熱心に議論している大きなオンラインフォーラムを想像してください。よく見ると、三つの顕著な議論のカテゴリーがあります:電気車に対する愛を声高に語る人たち、SUVの耐久性を信じ切っている人たち、そしてスポーツカーのスピードとデザインに夢中になっている人たち。
K平均法クラスタリングを使用するというのは、これらのフォーラム参加者をそれぞれの好みに基づいたグループに整理するようなものです。それぞれのクラスタ内で、その車のタイプに対する一般的なセンチメントを最も的確に反映しているレビューを特定します—まるで各グループで最も熱心な愛好者を見つけるようなものです。
このレビューは、クラスタの「中心」と見なされ、その集団のセンチメントのスナップショットとして機能します。この作業を各クラスタに対して行い、これらの中心レビューを連結してから、Sentence-BERTモデルを通じてエンコードします。これにより、各車モデルに対するコミュニティのセンチメントを包括する頑健で多面的なベクトルが生成されます。
6.4 考察
強み:この方法の顕著な強みの一つは、レビューの豊かさと多様性を捉える能力です。それらをクラスタに分けることで、多様な意見が認識され、代表されることを確保します。
トレードオフ:しかし、多くの高度な方法論と同様に、トレードオフがあります。達成された分析の深さは、増加した計算要求によるコストがかかります。特に大規模なデータセットを扱う場合、クラスタリングプロセスはリソースを多く消費する可能性があります。
人気のない車モデルに関する課題:私たちが気づいた一つの問題は、レビューが少ない車モデルが私たちの分析で高くランクされ、結果が不一致になる可能性があるということです。これは、調査結果を解釈する際に考慮する必要がある制限です。
信頼性のある結果のためのフィルタリング:少なくとも20件のレビューを持つ車モデルに焦点を当てると、より信頼性があり、関連性のある結果が得られることがわかりました。これにより、あまり知られていないモデルの偏り効果が最小限に抑えられます。
クラスタリングは、さまざまな車モデルに対するユーザーのセンチメントを捉える単一のベクトルを生成するための、平均法よりも洗練された方法を提供していましたが、私たちの旅はまだ完了していません。さらに探求すると、ユーザーレビューからこれらの代表的なベクトルを合成する方法を洗練するために、さらに高度なAI駆動の技術が待ち受けています。
7. 方法その3: テキスト要約モデルを活用した車レビューの凝縮
異なる車モデルに対するユーザーレビューの本質をキャプチャする単一のベクトルを合成するための探求は、テキスト要約モデルを試すに至りました。主な目的は、入力できるレビューテキストの量を制限するトークン制限に対処することでした。
7.1 定義
テキスト要約とは、広範なテキストコンテンツを短縮しながらも意味のある要約に変換する技術駆動型のアプローチです。私たちのプロジェクトの範囲では、これは長くて多様な車のレビューを、コンパクトでありながら感情が豊かな要約に変換する強力なツールとして機能します。
7.2 課題と目標
課題:私たちが使用しているSonoisa Sentence-BERTモデルは、トークンの上限が512であり、これがレビューテキストの入力量を制限して重要な情報が失われないようにします。
目標:各車モデルのすべてのレビューを切り詰めることなく、また顕著な情報を失うことなく効果的に包括する単一のベクトル表現を作成することです。
7.3 提案手法
テキスト生成モデルによる要約:この課題に直接対処するために、MT5やOpenAIのDavinciのようなテキスト生成モデルを探索しました。これらのモデルは、元のレビューから最も重要な情報を保持する要約を作成するのが得意です。
要約の利点:
- Sonoisa SBERTによって課されたトークン制限を回避するのに役立ちます。
- 大量のレビューを効率的に処理できます。
- 基本的な内容を保存するため、代表的なベクトルを生成するのに適しています。
ワークフロー:
- 車のレビューを前処理し、トークン化します。
- テキスト生成モデルを使用して、各レビューの要約を作成します。
- これらの要約されたテキストから固定サイズの埋め込みを生成するためにSonoisa SBERTを使用します。
7.4 方法その3.0: MT5日本語モデルによる予備実験
私たちのテキスト要約への最初の試みは、主にその無料可用性から、MT5日本語モデルで始まりました。
7.4.1 モデルについて
- モデルの発見:このモデルは、日本語のテキスト要約に特化して最適化されたGoogleのMT5(Multilingual T5)モデルのファインチューニング版です。
- 多言語対応:このモデルはT5モデルの機能を拡張し、翻訳、要約、分類、質問応答といった一連のNLP(自然言語処理)タスクに適応できます。
- 訓練データ:このモデルは、XL-Sum日本語データセットからのBBCニュース記事で訓練され、ニュースストーリーの要素を取り入れたテキストの要約に最適化されています。
7.4.2 制限事項
不完全または欠落した情報:一般的にはモデルの性能は良好でしたが、レビューから重要な詳細を省略することが時々ありました。
- 入力例:「家の近所に買い物など、短距離のチョイ乗りなら十分役目ははたせますが. プライスに見合った価値はあるし、個性的な車好きには強くお薦め出来るが、日本車的な気軽さを求める人にはお薦めしない。」
- 出力された要約:「日本の車好きにはお薦めしない。」
- 出力結果の解説:元のテキストでは、車は自宅近くでの買い物など短距離に適しており、ユニークな車が好きな人におすすめだと言及しています。しかし、日本車のカジュアルな感じを求める人にはおすすめできないとも述べています。要約は最後の意見だけを抽出しています。
意味の変更:いくつかのケースで、要約されたテキストの意味が元のレビューの意図から逸脱していました。
- 入力例:「小回りが良い感じですね、あまり見掛けないですねかわいくて乗り心地もそこそこ。燃費がやたらといいです 軽トラックもありますが同じくらいです。ボディサイズがコンパクトで取り回ししやすく運転しやすかったです。パワーも不足感がなく十分に楽しめました。」
- 出力された要約:「軽トラックで運転しやすかった。」
- 出力結果の解説:元のテキストは、車の操縦性、燃費効率、十分なパワーなどを賞賛しています。要約は誤って、車が軽トラックのように運転しやすいと示唆しており、他の側面を見落としています。
多数意見の見落とし:時折、モデルはレビュワーの多数が表現した感情を把握できませんでした。
- 入力例:「やっぱり 古い 。燃費がやたらといいです 軽トラックもありますが同じくらいです 。古いのでかっこがわるいです。」
- Summary:「燃費がやたらと良い。」
- 出力結果の解説:元のテキストでは、車が古くてあまりスタイリッシュでないが燃費が良いと言及しています。特に、車が古いという事実は元のレビューで何度も言及されています。この繰り返しにもかかわらず、要約は燃費が良いという点だけを抽出し、車の年齢について頻繁に言及されている点を省略しています。
7.4.3 結論
- これらの制限にもかかわらず、MT5日本語要約モデルは、レビューにおける全体的な感情を把握するために有望です。
- 車のレビューという領域でより信頼性のある要約を生成するためには、モデルの追加的なファインチューニングと最適化が必要です。
7.5 方法その3.1: OpenAIのText-Davinci-003モデルを用いた高度なテキスト要約
MT5モデルにおける制限に対処するため、より優れたテキスト要約能力を持つOpenAIのText-Davinci-003モデルに転向しました。OpenAIのCodexシリーズの一部であるText-Davinci-003は、GPT-3.5アーキテクチャから派生しています。その広範な知識ベースと高い適応性のおかげで、さまざまなNLPタスクで優れた性能を発揮します。注目すべき機能には、要約、翻訳、質問応答が含まれています。また、特定のアプリケーションに対してファインチューニングすることも可能です。
7.5.1 手続き
- モデルの統合:Text-Davinci-003モデルは生のレビューを取り込み、簡潔でありながら意味のある要約を生成します。APIが内部でこれを処理するため、トークン化は必要ありません。
- 出力品質:短さにもかかわらず、モデルの要約は元のレビューの本質と感情を保持し、代表的なベクターを合成するための豊富なデータを提供しています。
7.5.2 スタートシーケンス
スタートシーケンスとは、要約、翻訳、または任意の形で分析したいコンテンツの前に配置するテキストの断片のことです。このシーケンスは指示として機能し、モデルに期待される出力のタイプについて知らせます。例えば、スタートシーケンスは「以下を要約せよ:」といった単純なものから、「肯定的な側面、否定的な側面を特定し、全体的な評価を行え」といった具体的なものまで様々です。
目的とユーティリティ
スタートシーケンスを使用する目的は、モデルに対する計算上の文脈を設定することです。それによって:
- 出力を形作る:異なるスタートシーケンスは、要約の様々な形と精度を生み出すことができます。
- 特定性を追加:よく設計されたスタートシーケンスは、モデルに対して特定の側面(例えば、長所、短所、または全体的な評価など)に焦点を当てるように命じることができます。
- 一貫性を向上:複数のレビューにわたって標準化されたスタートシーケンスを使用することで、要約が一貫した方法で生成されるようになり、それらを比較・対照することが容易になります。
- 粒度を高める:スタートシーケンスの選択は、要約の詳細レベルに影響を与え、広範な概観またはニュアンスのある解釈を提供することができます。
私たちのプロジェクトに対する影響
Text-Davinci-003を用いた実験において、スタートシーケンスの選択が生成される要約の品質と粒度に顕著な影響を与えることがわかりました。使用するスタートシーケンスを微調整することで、プロジェクトのニーズにより適した形で、モデルの挙動をカスタマイズすることができました。これにより、簡潔な要約や詳細な分析を生成する場合でも対応できました。
スタートシーケンスの実験
要約の品質を測定するために、異なるスタートシーケンスを使用してテストを実施しました。
ケーススタディ: 3つのレビューに対するスタートシーケンスの違い
3つの車のレビューを連結し、異なるスタートシーケンスを用いて様々な要約を生成しました。
使用したテキスト:
| レビュー1 | 【総合評価】 おおむね満足です。中古車での購入でしたが元気に走ってくれています。 【良い点】 やっぱり燃費性能は満足です。前車は軽のターボ車で15キロ/L程度でしたが、現在のプリウスは平均で22キロ程度は走ってくれます。(使用エリアは大阪です。) またゆっくり走っている分には、社内も静かです。エルグランドも所有しておりますが、それよりも静かかも・・・ 【悪い点】 高速走行は余裕がないように感じます。アクセルを踏み込めばそれなりに走るんですが、とたんに燃費がダウン。またエンジン音もうるさくなるのでアクセルを踏みたくなくなります。 |
| レビュー2 | 【総合評価】 確かに燃費はいいが他車種に比べて割り高な感じはします。 周りと同じでいいという方にはおススメですが、走る楽しみは感じられません。 【良い点】 燃費がいい。環境に意識していると周りから思われる。車内が静か。 【悪い点】 信号待ちで、「周りがプリウスだらけ」に遭遇する。 静かすぎて前方の歩行者が気付いてくれない。 |
| レビュー3 | 【総合評価】 老若男女を問わず誰でもすんなり受け入れられるクルマだと思います!使い勝手も従来のセダン、ハッチバックとそん色なく利便性も兼ね備えたクルマです。 【良い点】 燃費は勿論、落ち着いた外観、内装が◎ 【悪い点】 ハイブリッドが故に加速に物足り無さを感じる時があります。 |
結果
スタートシーケンス:「要点を抽出します:」
| ・燃費が良い |
| ・落ち着いた外観 |
| ・内装 |
| ・ハイブリッドなので加速が物足り無い |
スタートシーケンス:「良い点、悪い点、総合評価を抽出します。」
| 【良い点】 燃費性能、落ち着いた外観、内装、利便性がある。 |
| 【悪い点】 高速走行時の加速性能に不満がある。 |
| 【総合評価】 プリウスは燃費性能が高く、落ち着いた外観、内装、利便性も兼ね備えたクルマです。高速走行時の加速性能に不満がありますが、全体的に満足できるクルマだと思います。 |
ケーススタディ: 18のレビューに対するスタートシーケンスの違い
簡潔性のためにレビューテキストは省略されていますが、トヨタ・プリウスという車種に対応する18のレビューを用いて、スタートシーケンスの効果性を評価しました。
ケース1: オールインワンサマリー
長所、短所、および全体的な評価を一度に取得します。
- 連結されたフィールド:
eval_comprehensive - トークン数:2,902
- スタートシーケンス:「良い点、悪い点、総合評価を抽出します。」
- 応答サマリー:
| 【良い点】 燃費が良い。ハイブリッドなので優秀です。静か。スタイリッシュなデザイン。 |
| 【悪い点】 少し値段が高い。車内空間が狭い。 |
| 【総合評価】 とても良い車です。静かで燃費が良く、デザインもスタイリッシュなので、とても満足しております。 |
ケース2: 個別の側面のサマリー
合計トークン数は2,367になります。太字で示されているのは、ケース1と比較して抽出された追加情報です。
良い側面:
- 連結されたフィールド:
eval_like - トークン数: 655
- スタートシーケンス:「車のこれまでの良い点をまとめる:」
- 応答サマリー:
| 燃費、静粛性、低燃費、スタイリッシュなデザイン、乗り心地が良い。 |
悪い側面:
- 連結されたフィールド:
eval_dislike - トークン数: 683
- スタートシーケンス:「車のこれまでの悪い点をまとめる:」
- 応答サマリー:
| ・燃費が実際よりも低い ・広さが狭めな ・静粛性がない ・乗り心地が少々難しい ・値段が少し高め |
総合評価:
- 連結されたフィールド:
eval_comprehensive - トークン数: 1029
- スタートシーケンス:「これまでの車のレビューをまとめます:」
- 応答サマリー:
| 燃費がとても良く、安定してて、高性能なエンジンで、見た目もスタイリッシュで、乗り心地も良く、エアバッグやABSなどのセーフティー装備も充実しています。 |
情報損失の分析
スタートシーケンス「良い点、悪い点、総合評価を抽出します。」は3つの連結されたレビューに対してはうまく機能しましたが、18のレビューセットに対しては過度に短縮された要約を生成しました。
ケース1では、要約は良い燃費効率やスタイリッシュなデザインといった重要な要素をいくつか捉えていますが、ケース2の要約よりも明らかに詳細が少ないです。
ケース2では、各側面(長所、短所、全体的な評価)が個々に要約されており、より粒度の高い、ニュアンスのある要約となっています。例えば、ケース2の eval_dislike (評価での嫌いな点)の要約は、高い価格だけでなく、「静寂性がない」や「若干乗りにくい」といった追加の点も捉えています。
この比較からは、特定のニーズに合わせて start_sequence を調整する重要性が明らかになります。
7.5.3 実装戦略
私たちの実装戦略の進化は、要約の品質とコスト効果のバランスを取ることを目指しています。
初期戦略と改訂戦略:最初は、連結されたレビューの3000トークンの塊を要約することを目的としていました。しかし、コストの問題から、このアプローチは後に修正されました。
スタートシーケンスのカスタマイズ:特に大量のレビューを扱う際に、要約生成のためのスタートシーケンスを変更することで、より良い粒度を実現しました。
価格とトークンの見積もり:すべてのレビューで合計16,872,777トークンと見積もられ、1kトークンごとに0.02ドルのコストがかかるため、初期戦略では320ドル以上のコストが発生することになります。
改訂戦略:コストを抑制するため、各車種の連結されたレビューを最大3000トークンまで要約することにしました。また、レビューが20件以上あるモデルを優先して、車種のサンプルサイズを458に減らしました。このアプローチは、重要な情報を保持しながら効率を優先することを目的としています。
パイプライン:
K平均法レビュー選択:各車種グループに対して、K平均法クラスタリングを用いて、トークン数が最大3000までとなるようなK件のレビューのグループを見つけ出しました。K平均法アルゴリズムは、その選択に際してeval_comprehensive(総合評価)フィールドのベクトル表現を用いました。
連結と準備:レビューが選ばれた後、各グループに対してeval_comprehensive(総合評価)、eval_dislike(嫌いな点)、eval_like(好きな点)のフィールドを個別に連結しました。この方法によって、各レビュータイプの整合性を維持できました。
カスタマイズされた要約:その後、レビューの各カテゴリ(eval_comprehensive、eval_dislike、eval_like)に対してカスタマイズされたスタートシーケンスを用いて要約を生成しました。例えば、使用されたスタートシーケンスは次のようなものでした:
| Field | Start sequence |
|---|---|
eval_comprehensive |
これまでの車のレビューをまとめます: |
eval_dislike |
車のこれまでの悪い点をまとめる: |
eval_like |
車のこれまでの良い点をまとめる: |
- 最終フォーマット:これらの要約は、次の形式で連結されました:
"【良い点】\n {eval_like_summary}\n【悪い点】\n{eval_dislike_summary}\n【総合評価】\n{eval_comprehensive_summary}" - ベクトル埋め込み:その後、Sonoisaモデルが各要約から代表的なベクトルを生成するために使用されました。
7.5.4 Text-Davinci-003によるテキスト要約の使い方
テキスト要約にText-Davinci-003モデルを使用する方法に興味がある方のために、ステップバイステップのガイドを以下に示します:
- APIキー登録:モデルと対話するためにはAPIキーが必要です。ユーザー設定のAPIキーのセクションで申し込むことができます。
ライブラリのインストール:OpenAIのPythonライブラリをインストールします。pipを使用して簡単にインストールできます。
pip install openaiテキストの準備:テキストがよく構造化されていることを確認してください。手動でのトークン化は不要です。
Completions APIリクエストの設定:API呼び出しパラメータは以下のように設定する必要があります:
- プロンプト: 要約する入力テキストをプロンプトとして定義します。 テキスト要約に効果的なスタートシーケンスを決定します。
- モデル:モデルをtext-davinci-003として指定します。
- 最大トークン数:max_tokensパラメータを設定して、要約の長さを制限します(例:1000トークン)。
- 温度:テキスト生成におけるランダム性のレベルを制御するために、temperatureパラメータ(例:0.7)を選択します。
- Top_P:生成されたテキストのサンプリングを制御するために、top_pパラメータ(例:1)を設定します。
API呼び出しを行う:設定されたパラメータでAPI呼び出しを行うために、OpenAIのPythonライブラリを利用します。
以下のPythonコードのスニペットを使って要約を生成することができます。
import openai openai.api_key = "your-api-key" text = "Your text here." start_sequence = "Summarize the following:" response = openai.Completion.create( model="text-davinci-003", prompt=f"{text}\n{start_sequence}", temperature=0.7, max_tokens=256, top_p=1, frequency_penalty=0, presence_penalty=0 ) summary = response['choices'][0]['text'].strip() print("Summary:", summary)結果の分析:生成された要約の内容とセンチメントを精査して、ソース素材と整合していることを確認します。Text-Davinci-003の潜在能力に関する詳細は、公式ドキュメントを参照してください。
7.5.5 費用対効果
| 費用 ($) | プロンプトトークン | 生成されたトークン | 合計トークン | 平均トークン / レビュー | 平均費用 / レビュー ($) | |
|---|---|---|---|---|---|---|
| 「良い点」テキスト要約 | 8.15 | 339735 | 69190 | 408925 | 78.44 | 0.0016 |
| 「悪い点」テキスト要約 | 6.43 | 268873 | 61323 | 330196 | 63.34 | 0.0013 |
| 「総合評価」テキスト要約 | 9.38 | 362735 | 97297 | 460032 | 88.25 | 0.0018 |
| 合計 | 24.78 | 971343 | 227810 | 1199153 | 230.03 | 0.0047 |
費用詳細:Text-Davinci-003モデルを要約に使用した総費用は24.78ドルで、これには5,213件のレビューが含まれていました。1レビューあたりの平均コストは約0.0047ドルでした。
7.5.6 課題と考察
フォーマットの不一致:一つの障害として、異なる要約レビュー間でフォーマットが変わることがあり、その結果、一様な表示が複雑になることがありました。
コストの考慮:Text-Davinci-003モデルを利用することは費用がかかるもので、データセットの要約には320ドル以上が必要でした。ただし、予算が制約でない場合、要約の品質はその費用を正当化します。
スタートシーケンスの適応:一つの洞察として、スタートシーケンスが要約の品質に大きく影響することがわかりました。異なるスタートシーケンスを異なる連結レビューセットで試すことにより、要約における詳細の捉え方を改善することができました。
7.5.7 本節のまとめ
私たちはText-Davinci-003が高品質な要約を生成できることを確認しました。主な課題は、高い費用と要約全体でのフォーマットの一貫性を確保することにあります。それでも、予算の制約が最小限であれば、このモデルは有望な結果を提供します。
このテクノロジーがどのように機能するのかを実際に確認できるデモサイトを公開しています。ぜひ、デモサイトを訪れてみてください。
8. まとめ
日本語の車のレビューを分析する過程で、3つの異なるAI駆動の方法論を通じて、一概にすべてに適用できる方法はないことが明らかになりました。各方法がその独自の側面で私たちの理解に貢献していますが、さらなる探求が必要な課題も提起しています。
8.1 方法のまとめ
方法その1:レビューの車ベクトルの平均算出 は、多様な感情を単一のベクトル表現にまとめる簡単な方法を提供しました。しかし、この方法のシンプルさはその強みでもあり、その弱点でもありました。平均化されたベクトルでは、対照的な意見の間の線がしばしばぼやけてしまいました。
方法その2:K平均法クラスタリングとSBERTモデルエンコーディング は、分析に深みと粒度を追加しました。レビューをクラスタリングし、その後エンコードすることで、感情のより豊かなスペクトルを捉えることができました。しかし、このアプローチはより多くの計算リソースを要求し、クラスタリングに関連する複雑さも導入しました。
方法その3:OpenAIの要約(Text-Davinci-003モデル) は、AI駆動のテキスト要約の潜在能力を示しました。Text-Davinci-003モデルは、簡潔でありながら文脈が豊富な要約を生成し、長いレビューの要点を抽出するのが容易になりました。一方で、コストの問題とフォーマットの不一致が障壁となっています。