

Table of Contents
- Introduction
- Sunday: Tutorials
- Monday: Day One
- Tuesday: LLM Day
- Wednesday: Government Day and SIRIP
- Final Remarks on Conference Content
- Final Remarks on Event Organization
Introduction
Last month I attended The 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. This time it was held in Washington D.C., USA, from July 14th to the 18th. This forum showcases the latest research results and techniques in IR. The conference spanned five days, featuring papers, system demonstrations, posters, doctoral consortiums, tutorials, and workshops. In addition to the traditional sessions, this year’s SIGIR included an industry track (SIRIP), a government day, a Large Language Model Day, and other special events.
 |
|---|
| The event venue was the Capital Hilton Hotel |
As a representative of RONDHUIT, along with my colleague Lara Solà, this event was particularly significant for me given its nature and contents. Also, it was my first time meeting a colleague in person after spending an extended period in my home country!
During the conference, I had the opportunity to listen to numerous presentations throughout the day. Given the volume of sessions, it's impossible to provide detailed feedback on every presentation, so I will give a very brief summary of the ones I attended and highlight only the ones I personally found more interesting.
Sunday: Tutorials
The first day was dedicated to tutorials, offering deep dives into various subjects. Here are the tutorials I attended:
- Large Language Model Powered Agents for Information Retrieval: This tutorial provided an in-depth look at how LLMs can enhance IR tasks, covering the fundamentals and advanced techniques.
- Empowering Large Language Models: Tool Learning for Real-World Interaction: Focused on leveraging LLMs for real-world applications, this session highlighted practical implementations and challenges.
- Robust Information Retrieval: Discussed methods to ensure robustness in IR systems, essential for handling diverse and unpredictable data.
 |
|---|
| The first day was dedicated to tutorials |
Although the sessions were called ‘tutorials,’ this time around there was no hands-on experience, which I found strange.
Monday: Day One
The first official day of the conference featured multiple sessions. Here’s a brief overview of the ones I attended:
Session 1: Evaluation
Evaluation in IR is crucial for assessing the effectiveness and efficiency of search algorithms and systems. This session focused on various aspects of evaluation, addressing both theoretical and practical concerns. One paper delved into the challenges of handling ties in IR ranking, proposing methods to improve accuracy. Another emphasized the importance of contextualizing statistical significance to avoid misleading conclusions in IR studies. Yet another study explored the reliability of fairness evaluations in recommender systems, highlighting the interplay between fairness and relevance. Finally, a discussion on the critical components of evaluation metrics provided insights on what constitutes meaningful evaluation in large-scale search systems. These papers collectively contribute to a deeper understanding of evaluation methodologies, ensuring that IR systems are both effective and equitable.
Session 2: Multilingual Retrieval
Multilingual retrieval has become more important as global communication expands and the need for cross-language search capabilities grows. This session explored innovative techniques to enhance retrieval across multiple languages. One study focused on improving dense passage retrieval through advanced negative sampling techniques, which optimize the retrieval process in multilingual settings. Another paper introduced methods for aligning multilingual data using meta-distillation, facilitating more accurate and effective semantic retrieval. These advancements are especially relevant to RONDHUIT and our product KandaSearch, underscoring the importance of developing robust multilingual search capabilities to meet the demands of a diverse, global user base.
Session 3: RecSys and Social Media
This session was about the use of recommender systems in social media, focusing on how user behavior and preferences are modeled and utilized. One paper explored the use of user simulation techniques using LLMs to minimize live experiments in production recommender systems. Another study examined the evolution of behavioral embeddings in social media recommendations, with a specific focus on platforms like Snapchat. The session also included an analysis of search spell correction techniques in Amazon Music, demonstrating how precise corrections can enhance user experience.
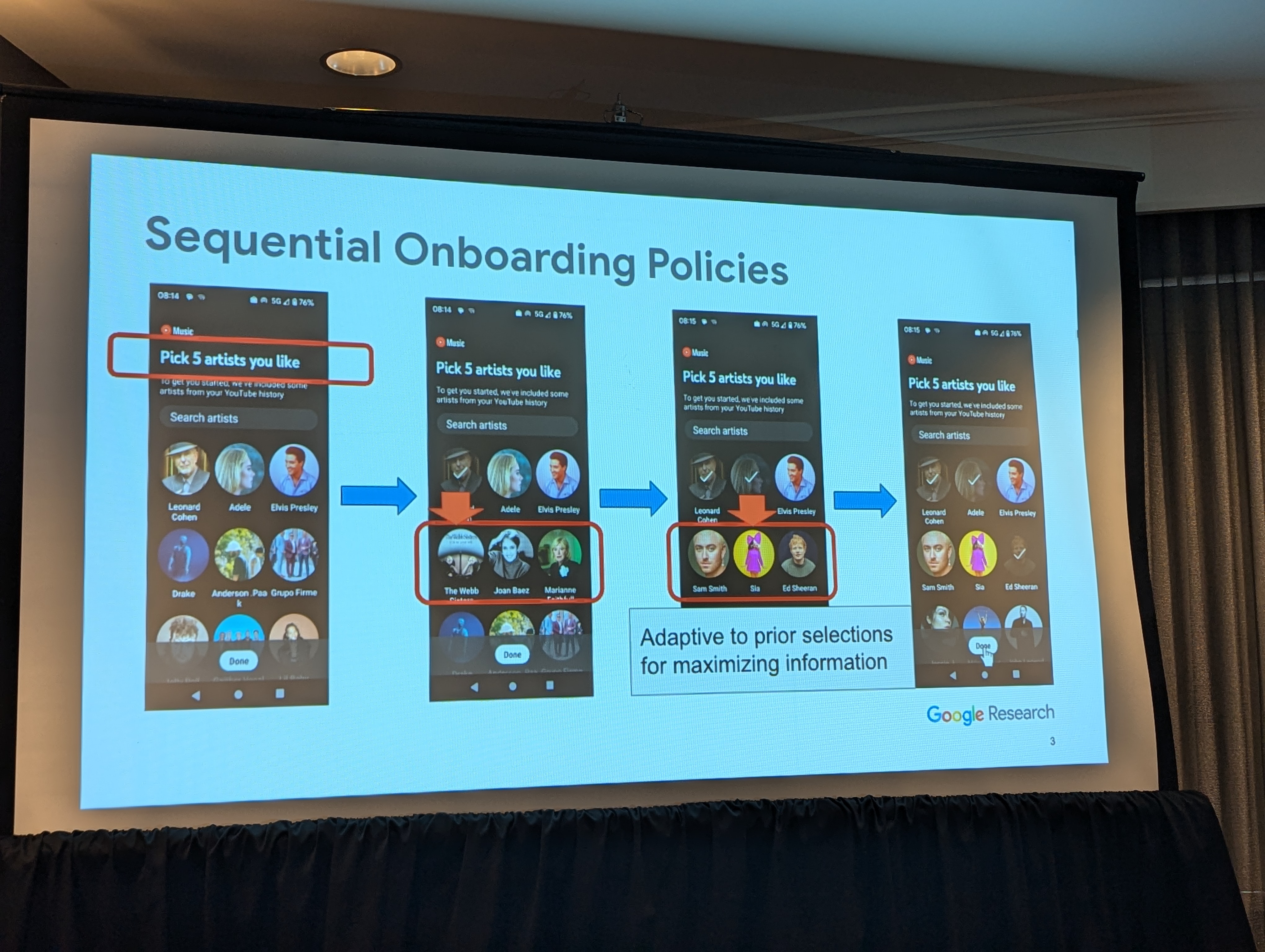 |
|---|
| Slide from Minimizing Live Experiments in Recommender Systems: User Simulation to Evaluate Preference Elicitation Policies |
Tuesday: LLM Day
LLM Day focused on the revolutionary role of Large Language Models like GPT-4 and LLaMA in search and recommendation systems. The sessions covered advancements in LLM research, open-source development, and their integration with IR, addressing key topics such as inference efficiency, synthetic data generation, long-context understanding, and AI ethics. This day provided a comprehensive look at how LLMs are reshaping the future of these technologies, encouraging collaboration and knowledge exchange among experts.
Favorite Paper: Dimension Importance Estimation for Dense Information Retrieval
One of the standout papers for me was on "Dimension Importance Estimation for Dense Information Retrieval." This research delves into the challenges of working with high-dimensional embeddings in information retrieval, where queries and documents are represented in a latent space. The authors hypothesize that by projecting these high-dimensional representations onto a query-dependent subspace, retrieval effectiveness can be significantly improved. They introduce a novel approach called Dimension Importance Estimators (DIME), which identifies and selects the most relevant dimensions for each query, thereby enhancing the quality of the search results.
This work is particularly important as it offers a way to optimize dense retrieval systems by focusing on the most impactful dimensions, akin to how Principal Component Analysis (PCA) reduces dimensionality in data while preserving the most critical information. Moreover, this technique can be compared to the role of stop-word removal in classical search; just as stop-words are filtered out to improve search accuracy, DIME selectively reduces the dimensionality of the representation space to boost retrieval performance. The paper demonstrates that this approach can lead to substantial improvements, with performance gains of up to 58.6% in certain scenarios, making it a significant advancement in the field of IR. Read the paper here.
Wednesday: Government Day and SIRIP
Government Day
Government Day focused on how governments are leveraging AI to benefit the public and enhance services that improve quality of life. The IR community is uniquely positioned to support these efforts by developing AI tools that provide precise and grounded results. While my primary focus is on research, and I am not very drawn to policy discussions, I recognize the critical role IR plays in shaping public policies and societal impacts through AI technology.
SIRIP Panel Discussion
SIRIP (SIGIR Symposium on IR in Practice) focused on bridging the gap between academia and industry, showcasing how IR technologies are applied in real-world scenarios. One of the highlights was a panel discussion featuring industry leaders and academic experts, who explored the future of search engines in the era of embeddings. The discussion centered around whether search engines will fully transition to embedding-based methods and the challenges this shift may present.
Key insights included the balance between engineering and scientific innovation, the computational complexities of using embeddings for large datasets, and the need for hybrid search approaches that combine traditional methods with embeddings. The panelists also addressed the practical challenges of maintaining multilinguality, ensuring data freshness i.e. dealing with new vocabulary, and dealing with the limitations of embeddings in capturing complex meanings.
Takeaways
A main takeaway for me is the idea that while embeddings are a powerful tool in IR, they are not a universal solution. For instance, in specific use cases like book search, relying solely on embeddings is impractical because users often search with exact identifiers like ISBNs, which can be efficiently retrieved with simple database lookups. The discussion also highlighted that the focus should shift from the numerical representations of data to understanding and fulfilling user intent. Language in IR isn't just about description; it's about enabling action.
The Poster Session also took place on this day.
Final Remarks on Conference Content
Throughout SIGIR 2024, it became evident just how transformative LLMs are in the field of IR and beyond. LLMs are being employed across a wide range of disciplines, significantly altering the way we approach and solve problems. In the IR domain, LLMs are now crucial for tasks like model selection in semantic search, allowing for more accurate and context-aware retrieval of information. They are also used to simulate user behavior, helping to address challenges like the cold start problem in recommender systems, where there is limited user data to inform recommendations.
Moreover, LLMs play a key role in defining user preferences, enabling systems to assign relevance and labeling with greater precision. They are also increasingly used for data pruning, refining datasets to improve model training efficiency. In the realm of query correction, LLMs enhance recall and precision, ensuring that users receive more accurate and relevant search results.
However, despite their versatility and effectiveness, LLMs come with significant challenges. They are computationally intensive, requiring substantial resources for both training and deployment. This not only drives up costs but also raises concerns about the accessibility and sustainability of such powerful models. As the use of LLMs continues to expand, it is essential to consider these trade-offs and strive for solutions that balance performance with practicality.
Final Remarks on Event Organization
While SIGIR 2024 offered a wealth of valuable insights, there were some organizational aspects that could be improved. The Tutorial Day, for instance, fell short of expectations. Instead of the hands-on sessions that many attendees hoped for, the day consisted primarily of lectures. This lack of practical engagement made the tutorials feel more like extended presentations rather than interactive learning experiences. I am not sure if this has been the case in previous years as well.
The quality of the presentations themselves also left room for improvement, particularly in their design. Many of the slides appeared to be direct screenshots from the papers, with dense text and minimal visual aids. This approach made the sessions feel static and less engaging, as the presentations often lacked the demonstrative elements needed to effectively communicate complex ideas.
The social events, designed to foster networking and community building, were somewhat disappointing. As a newcomer, I had hoped to feel more welcome, and as a queer person of color, I wish information about the DEI (Diversity, Equity, and Inclusion) events had been made more accessible.
Despite these shortcomings, the conference still provided valuable insights and networking opportunities. I look forward to next year’s event in Europe, expecting improved organization and more engaging sessions.
 |
|---|
| See you next year! |