

Previously Solr has an ability to create aliases for the cores in the Standalone mode, but they were limited and had some major problems and in the end this feature was dropped. But after introducing SolrCloud it was decided to bring back aliases feature for the collections. So what is aliases?
Aliases
Alias is an alternative name for the collection. Alias can be used, for example, to decouple client code from the Solr. If using aliases, client doesn't need to be aware of the internal structure of the Solr and what exact collection it is using for indexing or searching. That approach make it possible to switch from using one collection to another without affecting the client's code. All you need to do is to update an alias within the Solr to reference another collection. That can be useful for cases when old collection should be replaced with the new reindexed collection. And with the help of aliases the switch cab be done immediately with zero downtime.
But the most important part of the alias concept is that single alias can be assigned to the multiple collections. Using alias instead of the collection name will allow you to search for documents across all the collections that are part of the alias. The routing to the collections will be managed by Solr, so no additional efforts on the client side are needed.
Type of aliases
Solr provides two types of aliases: standard aliases and routed aliases. Routed aliases, in turn, devided into two additional types: time-routed aliases and category-routed aliases:
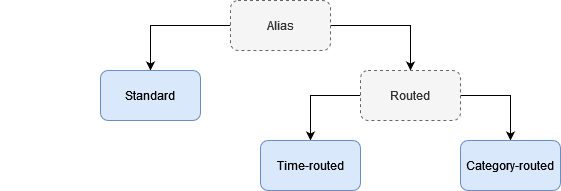
The standard aliases are quite privimitive. While they are allow searching across multiple collections, they will reject any update request in case alias can't be resolved to the single collection. To target this limitation routed aliases has been introduced. Routed aliases provides routing logic to redirect updates to the specific collection within the set of the alias collections. You can think of a routed alias as a super collection that just routes updates to the correct collection.
Time Routed Aliases
Time routed aliases represents the concept of the time ranged collections. You need to define start time of the alias and its interval and after that Solr will manage collections automatically. Every time the document is uploaded its time field will be checked, and based on the time field value, document would be routed to the corresponding collection.
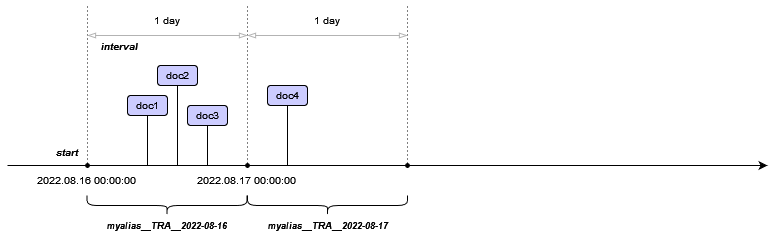
Let's say we have created an alias with the name myalias, and have defined the start time of 2022-08-16 00:00:00 with the interval value of 1 day. Initially, Solr will create the first collection for us:

All documents within the time range of 2022-08-16 00:00:00 to 2022-08-16 23:59:59 will be routed to the first collection:

What if the document will have a time value that is not fits in the range of the existing collection? For example, 2022-08-17 04:20:00. Solr will calculate the range for the next collection and will create it automatically. The range of the collection is calculated based on the start and interval values of the alias:
Note, that time routed aliases holds time ranged collections without a gaps. That means that Solr can create multiple collections to fill in the gap if needed:
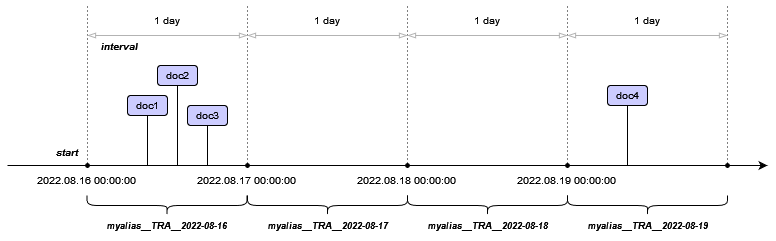
Also, note the collection name pattern myalias__TRA__2022-08-16. It consist of multiple parts. The first part myalias is the name of the alias this collection belongs to. Then follows the __TRA__ entry (TRA stands for time routed alias), and the last part 2022-08-16 is the start time of the collection range. So each following collections will have exactly the same name except the last part.
It is possible to make Solr automatically delete old collections in case of their range is exceeds the defined delete age limit. Each time a collection is created with the next range, Solr will check if some old collections need to be deleted. By default, no deletion is applied.
All alias related actions are handled by the collection handler. Following actions are available for the aliases:
- Create alias
- List aliases
- Update alias
- Delete alias
Create alias
An action CREATEALIAS should be used for creating alias. A set of parameters to apply is depends on what type of alias we are going to create. Below is the list of all the mandatory parameters for the time routed alias creation:
| Name | Description |
|---|---|
| name | The alias name to be created. |
| router.name | The type of routing to use. For the time routed aliases value time should be used. |
| router.field | The field of the document holding time value. |
| router.start | The start date/time of data for the alias |
| router.interval | An interval defining the time range of the collection. |
For example:
http://localhost:8983/solr/admin/collections?action=CREATEALIAS
&name=myalias
&router.name=time
&router.field=date
&router.start=NOW/DAY
&router.interval=%2B1DAY
&router.maxFutureMs=3600000
&create-collection.collection.configName=ldn
&create-collection.numShards=2
For parameters router.start and router.interval a so called Date Math expressions should be used. The first parameter uses value NOW/DAY, means get current date/time and round it to the start of the day. For the second parameter an expression +1DAY is applied, means add 1 day to the most recent collection to determine the next collection in the series.
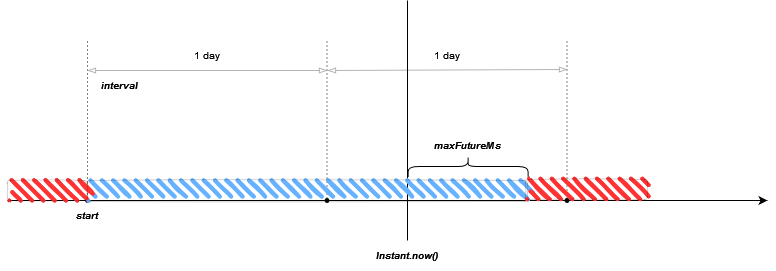
Also there were used some additional parameters. Parameter router.maxFutureMs defines an offset to allow indexing documents with some future dates. To understand the logic let's see how time routed alias make a decision what documents are allowed to be indexed, and what documents should be rejected.
Rule #1: documents that are in range from the start of the alias (i.e. start of the most early collection in the alias) to the current date/time (i.e. Instant.now()) are allowed. All document that have time before the start of the alias are always rejected.
Rule #2: documents that are in range from the current date/time (i.e. Instant.now()) plus
router.maxFutureMsoffset are allowed. All document that have time after the offset are always rejected.
Applying both rules the result will be as follows:
If you try to index document that have time before allowed range you will get an error:
{
"responseHeader": {
"rf": 1,
"status": 400,
"QTime": 307
},
"error": {
"metadata": [
"error-class",
"org.apache.solr.common.SolrException",
"root-error-class",
"org.apache.solr.common.SolrException"
],
"msg": "The document couldn't be routed because 2022-08-12T10:00:00Z is before the start time for this alias 2022-08-16T00:00:00Z)",
"code": 400
}
}
or another error in case of indexing document with the time that is too far in the future:
{
"responseHeader": {
"status": 400,
"QTime": 145373
},
"error": {
"metadata": [
"error-class",
"org.apache.solr.common.SolrException",
"root-error-class",
"org.apache.solr.common.SolrException"
],
"msg": "The document's time routed key of 2022-08-18T09:00:00Z is too far in the future given router.maxFutureMs=3600000",
"code": 400
}
}
Other two parameters are using create-collection prefix. That kind of parameters are applied during automatic collection creation and allows to define any parameter that are available for the collection create request. The only exclusion is name parameter, it can't be defined explicitly as Solr will automatically generate the name for the collection. In above example parameter create-collection.collection.configName defines what configuration to use for the collection, and parameter create-collection.numShards indicates how many shards should be used for the collection.
In case of alias was created successfully you can check it using Solr admin page:
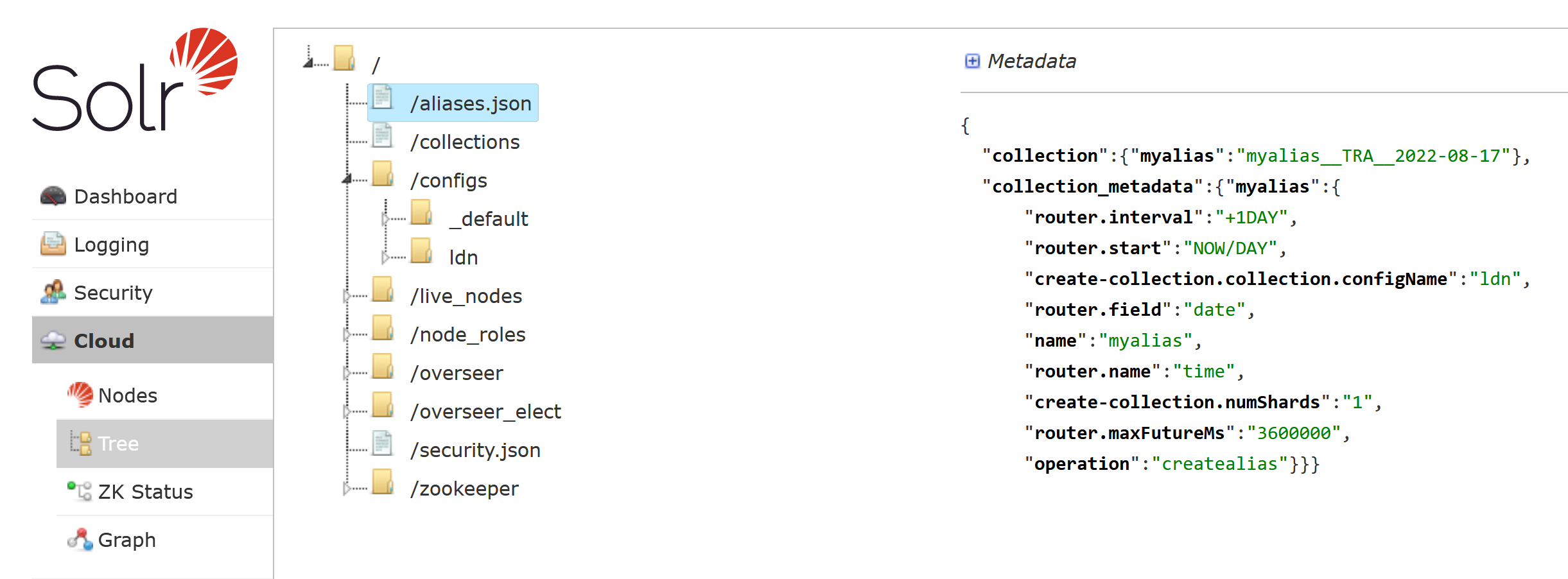
List aliases
Another way to check existing aliases is to run LISTALIASES action by executing following request:
http://localhost:8983/solr/admin/collections?action=LISTALIASES
No additional parameters are needed. As a response a list of all the avaiable aliases will be returned:
{
"responseHeader": {
"status": 0,
"QTime": 1
},
"aliases": {
"myalias": "myalias__TRA__2022-08-17"
},
"properties": {
"myalias": {
"router.interval": "+1DAY",
"router.start": "NOW/DAY",
"create-collection.collection.configName": "ldn",
"router.field": "date",
"name": "myalias",
"router.name": "time",
"create-collection.numShards": "1",
"router.maxFutureMs": "3600000",
"operation": "createalias"
}
}
}
Update alias
After alias is created it is possible to update its properties. In fact, the alias update logic makes no difference as to which properties will be updated. So it is possible to update any property. But it is not a good idea to update some major alias properties (like router.name or router.start) as Solr doesn't guarantee the correct behaviour after this. You should use this action with great care.
Here is an example of how to change value of router.maxFutureMs:
http://localhost:8983/solr/admin/collections?action=ALIASPROP&name=myalias&property.router.maxFutureMs=7200000
Note, that each property that need to be updated should be indicated using parameter with property prefix followed by the property name, like property.router.maxFutureMs.
Delete alias
In case you need to delete alias a special action DELETEALIAS should be used. Execute following query to delete indicated alias:
http://localhost:8983/solr/admin/collections?action=DELETEALIAS&name=myalias
Delete alias doesn't delete the underlying collections.
You can read about alias actions in more details at the Alias Management section of the official Solr documentation.
Limitations
While the alias concept looks promising, it has some limitations. The idea behind the alias was to make it transparent for the user, so that the user can work with the alias as if it were a collection name. But not all actions associated with a collection support aliases, or some of them may only partially support it. For example, it is not possible to delete collections backed by an alias. The collection delete logic will try to find a real collection with the given name instead. Backup of the collections supports only simple aliases and only in cases they are reference a single collection. And so on...
Also, the Solr documentation mentions about some possible problems with the document relevancy:
Any alias (standard or routed) that references multiple collections may complicate relevancy. By default, SolrCloud scores documents on a per-shard basis.
With multiple collections in an alias this is always a problem, so if you have a use case for which BM25 or TF/IDF relevancy is important you will want to turn on one of the ExactStatsCache implementations.
However, for analytical use cases where results are sorted on numeric, date, or alphanumeric field values, rather than relevancy calculations, this is not a problem.
Use cases
As you may noticed from the overall logic, time routed aliases are a perfect solution for some life-feed data like news, chat feeds or logs. The whole index can be automatically splitted into multiple time range collections giving an opportunity to optimize each of them. Since there are a low chances that documents will be indexed to the old collections we can optimize it by merging all the segments into one which will increase the search performance. Splitting is aslo prevents degradation of performance that can occur due to the continuous growth of a single index.
Another field of optimization is search. Search with an aliases is always applied to the whole set of the collections. This can be optimized by creating some special standard aliases like last-day, last-week, etc. and using search only against this limited set of the collections based on the time filter.