
TUTORIAL チュートリアル
03. 転置インデックスの基礎
このページの項目
「全文検索」とは、文書のすべてを検索できるものであり、文書の一部、例えばIDなどだけを検索対象とする「単なる検索」と区別されます。ここでは、検索エンジンが高速な全文検索を実現するのに用いている「転置インデックス」と、それを用いたキーワード検索、そして検索結果表示順を決定するスコア計算の基本について述べます。
転置インデックス方式に基づいた全文検索を理解されている方は、本章をスキップできます。
全文検索の検索方式
全文検索の検索方式には、大別すると順次検索方式と転置インデックス方式の2通りの方式があります。 順次検索方式は、検索時に指定された文字列と検索対象の文書を先頭から順次比較する方式で、Linuxのgrepコマンドや、RDBのlike検索がそれにあたります。 一方、検索エンジンで採用されている転置インデックス方式は、あらかじめ検索対象の文書からインデックスを作っておく方式のことで、文書にラベルを付け、ラベルで文書を引けるようにインデックスを作成します。
一般的に、RDBと検索エンジンには次のような違いがあります。
| RDB(リレーショナルデータベース) | 検索エンジン | |
|---|---|---|
| 特徴 | 関係モデル、トランザクション管理、CRUD | 高速な全文検索 |
| テーブル | 複数、正規化 | 単一、非正規化 |
| 検索 | SELECT、関係論理演算 | キーワード検索(AND/OR/NOT、表記揺れ、類義語、 ・・・)、セマンティック検索(KandaSearch) |
| 検索結果 | 集合、ソート | 関連度(クエリと文書の類似度)順 |
上表の通り、KandaSearchではセマンティック検索を取り扱うことができますが、以降は「キーワード検索」のみについて説明します。
転置インデックス
転置インデックスは、一般的には以下の手順で作成します。
例として、下の3つの文書を検索対象とする転置インデックスを作成します。
文書ID 文書テキスト
1 カツオはサザエの弟
2 サザエはワカメの姉
3 ワカメはカツオの妹
手順1
最初に、文書テキストを単語に分割し、単語と文書IDのペアにまとめます。
カツオ:1, は:1, サザエ:1, の:1, 弟:1,
サザエ:2, は:2, ワカメ:2, の:2, 姉:2,
ワカメ:3, は:3, カツオ:3, の:3, 妹:3
手順2
単語でソートし、同じ単語の文書IDを下図のようにまとめ、リストにします。これで転置インデックスが出来上がりました。
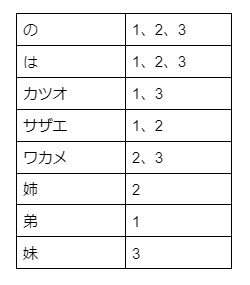
以降では「転置インデックス」を単に「インデックス」と呼ぶことにします。
検索
インデックスを用いて検索を行ってみます。
【例1】
以下の文書から、
文書ID 文書テキスト
1 カツオはサザエの弟
2 サザエはワカメの姉
3 ワカメはカツオの妹
以下のインデックスを作成・保持した検索エンジンがある時に、
「サザエ」で検索質問(q=サザエ)すると、
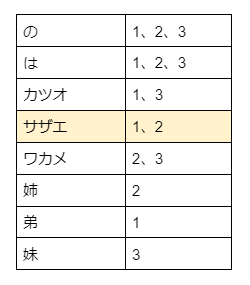
検索エンジンは、結果として、文書IDが1と2の文書を返します。
結果
カツオはサザエの弟 文書ID=1
サザエはワカメの姉 文書ID=2
質問を変えて検索してみます。
【例2】
以下の文書から、
文書ID 文書テキスト
1 カツオはサザエの弟
2 サザエはワカメの姉
3 ワカメはカツオの妹
以下のインデックスを作成・保持した検索エンジンがある時に、
「ワカメ AND 姉」で検索質問(q=ワカメ AND 姉)すると、
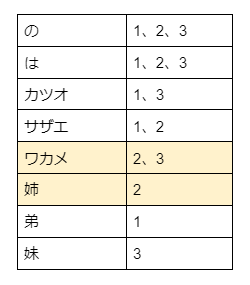
ワカメを含む文書IDは2と3、姉を含む文書IDは2で、その「AND」となるので、検索エンジンは、結果として、文書IDが2の文書を返します。
結果
サザエはワカメの姉 文書ID=2
さらに質問を変えて検索してみます。
【例3】
以下の文書から、
文書ID 文書テキスト
1 カツオはサザエの弟
2 サザエはワカメの姉
3 ワカメはカツオの妹
以下のインデックスを作成・保持した検索エンジンがある時に、
「ワカメ OR 妹」で検索質問(q=ワカメ OR 妹)すると、
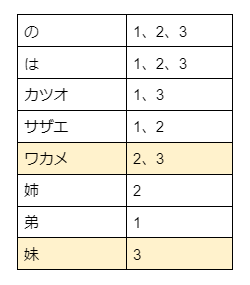
ワカメを含む文書IDは2と3、妹を含む文書IDは3で、その「OR」となるので、検索エンジンは、文書ID=2と3の文書を返しますが、その順番は、ID=3の文書を先に、次いでID=2の文書という順で結果を返します。
結果
ワカメはカツオの妹 文書ID=3
サザエはワカメの姉 文書ID=2
このように、検索結果の表示順をユーザーにとって好ましい順番で返却できることも全文検索エンジンがRDBと異なる点です。この表示順は、「スコア」を計算することで決定しています。
スコア計算
スコアとは、クエリ(q)と検索対象文書(d)の関連度を表す関数で、数値が大きいほど、両者の関連度が高いことを示します。
以下ではスコアの算出に「コサイン類似度」を使う場合を考えてみます。
score( q, d ) = cos( q, d )
コサイン類似度とは、比較する2つのベクトルのなす角度が小さいほど類似性が高いと判断するアルゴリズムのことです。なお、ベクトルとは「向き」と「大きさ」を持つ量で、ベクトル空間の次元数は、インデックス中の語彙数と等しくなります。しかし、以下の説明では簡略化し、クエリに用いられる単語数を次元数とみなします。
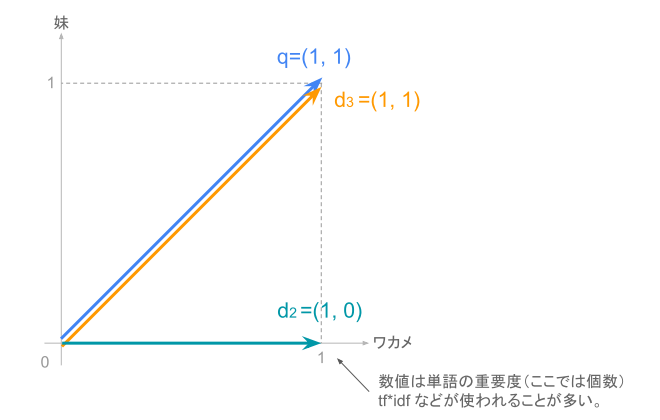
この図からわかる通り、クエリとd3のベクトルのなす角は0度となり、cos(q,d3)=cos(0)=1となります。 一方、クエリとd2のベクトルのなす角は45度となり、cos(q,d2)=cos(45)=0.525…となります。 文書3のスコアは1、文書2のスコアは0.525ですので、文書3のほうが検索語と文書の関連度が高いと判断できます。
図中のTF*IDFは単語の重要度を表す関数です。「文書中の単語の出現頻度(TF)」と「当該単語が出現する文書数(DF)の逆数(IDF)」から、クエリや文書中の単語の重要度を数値化できます。
上記での説明の通り、検索エンジンは、インデックスを作成したりスコアを計算したりするために、テキストを単語単位で扱う必要があります。英語などの文書は、単語間がスペースで区切られているので単語の境界は明らかです。一方、日本語テキストでは単語の境界は明瞭ではありません。
たとえば、「ここではきものを脱ぐ」という文書について、単語の境界は次のように考えられます。
ここ / では / きもの / を / 脱ぐ
ここ / で / はきもの / を / 脱ぐ
上記のように、単語を分割する位置次第で単語の持つ意味が変わることもあります。 このような課題を抱える日本語の文書を扱う上で、どのような方法で単語を分割すればよいのでしょうか?
日本語の単語分割方法
日本語の単語分割方法には、下記の2つのメジャーな方法があり、それぞれにメリット・デメリットがあります。
1. 形態素解析
- 辞書に基づいた単語分割。
- 検索結果は、検索誤りは低いが、検索漏れが発生しがち。
- タイムリーな辞書の更新が必要。
【分割例】
緊急事態宣言 → 緊急 / 事態 / 宣言
2. 文字N-gram
- 機械的にN文字単位に分割。2-gram、3-gramなど。
- 検索結果は、検索漏れは低いが、検索誤りが発生しがち。
- インデックスのサイズが大きくなる傾向あり。
【分割例】(N=2の場合)
緊急事態宣言 → 緊急 / 急事 / 事態 / 態宣 / 宣言
KandaSearchが提供する検索エンジンでは上記を両方とも使用可能で、業務要件に応じて使い分けたり、併用したりすることもでき、複雑な日本語検索の事情に対応可能です。