TUTORIAL チュートリアル
05. 検索
このページの項目
ここでは、KandaSearchの検索UIの利用方法や、検索を便利に、検索結果を見やすくするための手法などについて説明します。
検索UIから検索
前の章で登録したlivedoorニュースコーパスのインデックスに対し検索を行います。
ここでご紹介している機能とその操作内容は、検索UI内で使える機能のごく一部です。
詳細は、ドキュメントをご覧ください。
それでは、検索の操作を行ってみましょう。
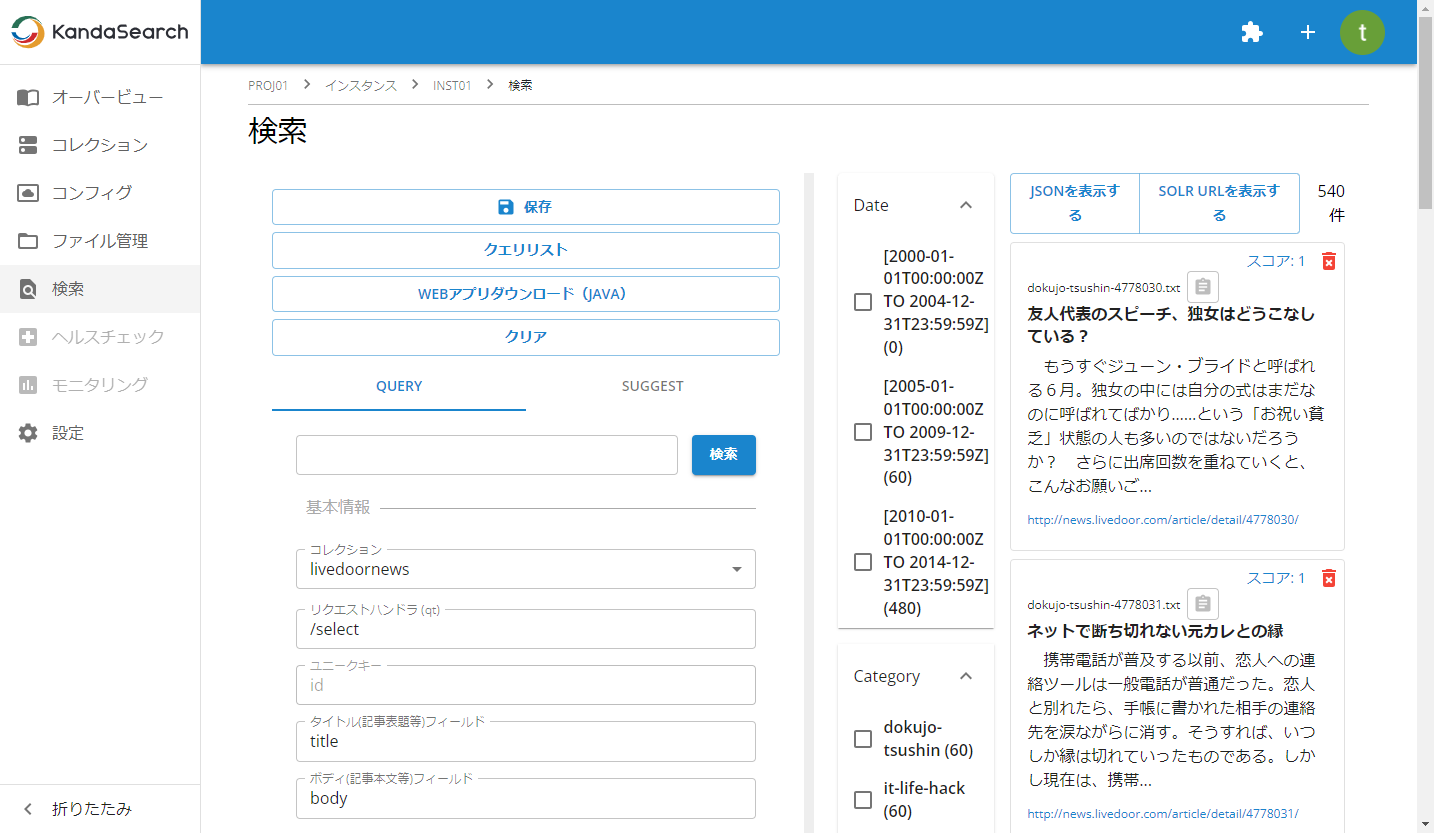
検索してみる
インスタンスビューの左サイドから「検索」をクリックします。
「コレクション」で「livedoornews」を選択し、青い「検索」ボタンをクリックします。
検索キーワードの入力ボックスに何も入れずに検索すると、以下のような画面が表示されます。
この画面の表示内容のポイントは次のとおりです。
- 左ペインには検索条件、右ペインには検索結果の表示
- キーワードを指定しなかったので全件が表示対象
- 1つの結果あたり表示されているのはIDのみ
- IDのテキスト上にマウスを合わせるとそのドキュメント内の他のフィールドの情報がポップアップ表示される
- 1画面の表示件数を超えた結果は、検索結果下部のページャーより表示できる

表示用フィールドを指定して検索してみる
次に、検索結果に他のフィールドの情報を表示させてみましょう。
KandaSearchの検索UIの検索結果表示では、1つの結果につき
- タイトル
- ボディ
- 画像
- URL
が表示されるようになっており、「スキーマ内で定義したフィールド名」をこれらに容易に指定できます。
左ペインで以下のように指定します。
- 「タイトル(記事表題等)フィールド」欄に「title」
- 「ボディ(記事本文等)フィールド」欄に「body」
- 「URLフィールド」欄に「url」
最後に「検索」をクリックします。
※このスキーマでは、検索結果のタイトル(記事表題等)にあたる部分のフィールド名がtitle、ボディ(記事本文等)にあたるフィールド名がbodyだったため(urlも同様)、このような指定となりましたが、タイトルやボディ、URLの欄には、スキーマ内で定義しているフィールド名を指定してください。
いかがでしょうか?
先ほどの表示よりも検索結果の表示項目が増えて、リッチな検索結果表示となったのではないでしょうか。
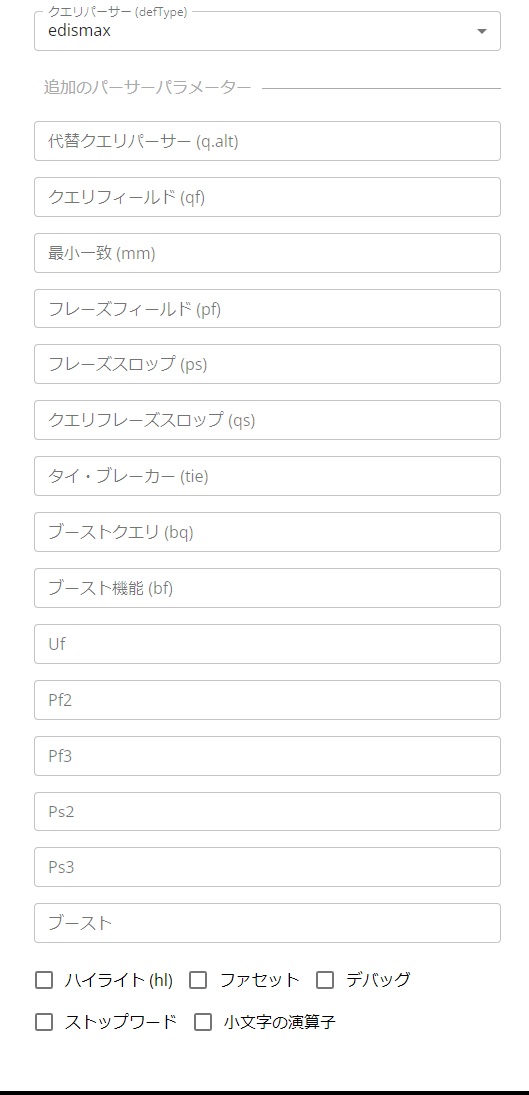
左のペインにおいて、クエリパーサー (defType)に一般的によく使われる検索手法である「edismax」を選択すると、指定できるパーサーパラメータが拡張され、より柔軟な検索が可能になります。
例えば、クエリフィールド(qf)にフィールド名を指定することで、検索時に横断するフィールドを指定できます。
キーワードを指定して検索
今度は、「検索キーワード」欄へキーワードを指定して検索してみましょう。
例えば、「コンピューター」と入力し「検索」をクリックすると、キーワードにヒットした結果8件が表示されます。
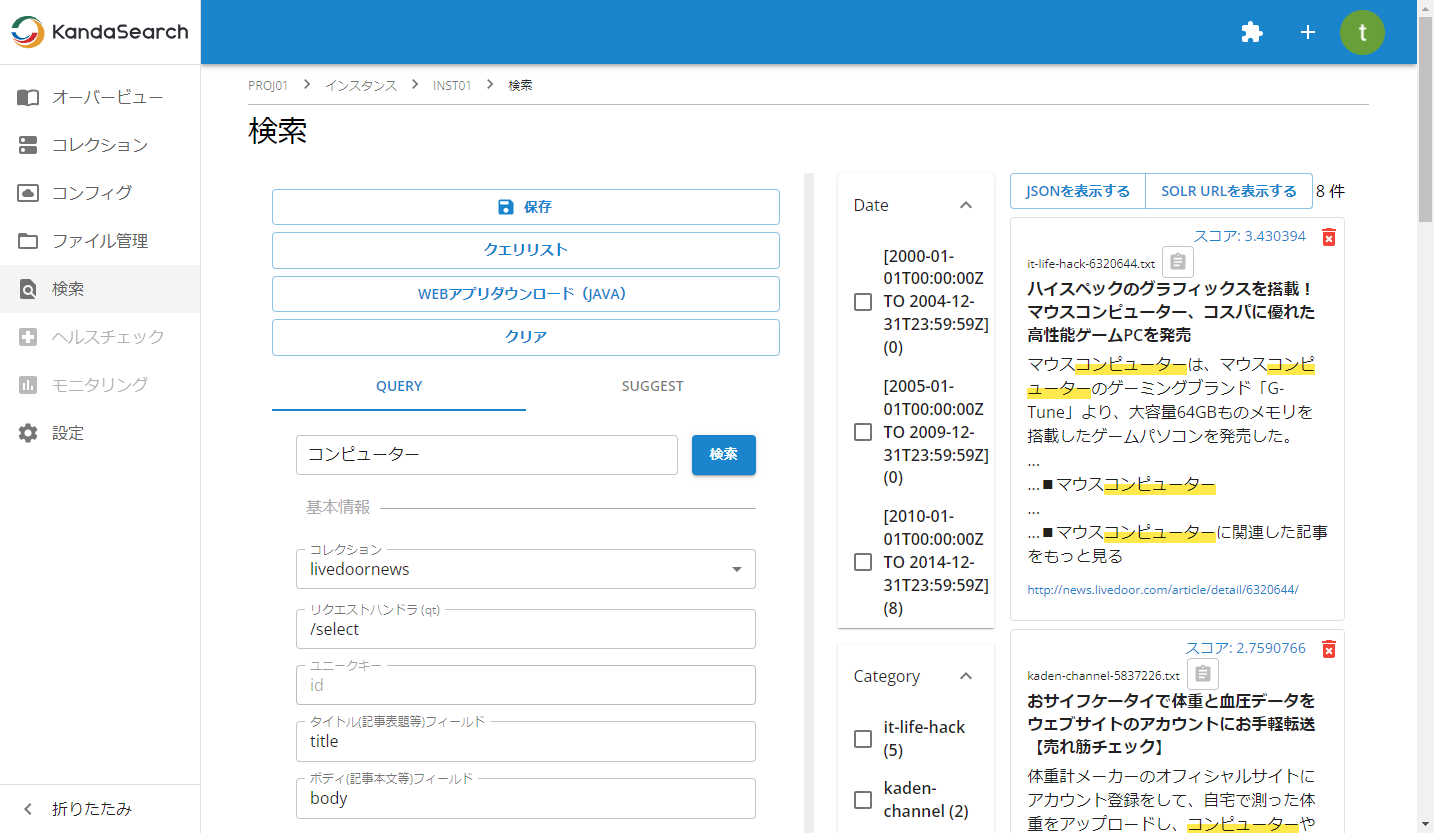
最適な検索結果が表示されるように、左ペインでいろいろな検索パラメータを指定して調整してゆきましょう。
テストに便利な機能
左ペインで指定する条件が増えてゆくと、それと同じ検索条件で検索するときの条件指定操作が面倒になってきます。その場合は、左ペインの「保存」のクリックで、表示中のクエリを名前を付けて保存することができます。
保存したクエリは「クエリリスト」から一覧の確認と読み込みができます。
また、保存したクエリは、プロジェクトのメンバー間で共有できますので、確認やデバッグにとても便利です。
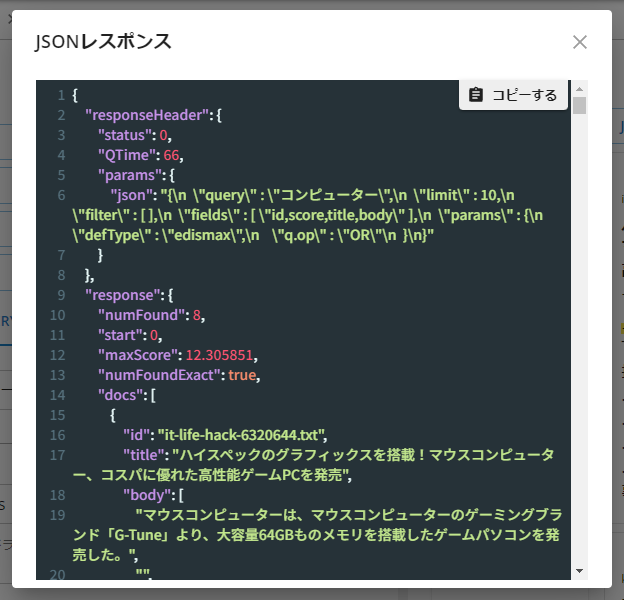
検索結果を表示させた後、右ペイン上部の「JSONを表示する」をクリックすると、検索エンジンからのJSON形式によるレスポンスを確認できます。
また、検索結果を表示させた後、右ペイン上部の「SOLR URLを表示する」をクリックすると、表示中のクエリの「検索リクエスト(HTTP GET)」のURLが表示されます。コピーしてからブラウザのアドレス欄に貼り付けて実行することで、生のレスポンスを確認することもできます。(この時、KandaSearch公式サイトのトップページにリダイレクトされる場合は許可されたIPアドレス範囲の指定に誤りがありますので、インスタンスビューの「設定」でIPアドレスの登録を行います)
ファセット
ファセットとは、検索結果の「内訳(カテゴリ的なもの)」をその件数とともに返却する機能です。
「ファセット」と「絞り込み検索」を組み合わせて使うことで、検索UIに次のような効果をもたらします。
- 検索時の条件指定で、属性(たとえば「ファイル種別」や「作成日」、「価格」など)を決定する必要がない。
- 検索結果を得るまでの操作が簡単。
- 「ヒット:0件」となるガッカリ感がない(検索結果を見ながら絞り込み検索ができるため)。
ファセットを利用するには、「ファセット」チェックボックスをオンにして、ファセットオプションを指定します。
オプションでは、以下の2種類の指定ができます。
- facet.field - フィールド名を指定します。フィールド値ごとの文書件数が返却されます。
- facet.query - 任意のクエリ(検索式)を指定します。当該クエリごとの文書件数が返却されます。
MEMO: この場合の「絞り込み検索」では fq パラメーターにクエリを指定します(ANDで q パラメーターに条件を付加するのは間違った使い方です)。
livedoorニュースコーパスのコンフィグでは、デフォルトでファセットが機能するように設定されており、検索結果の右ペインに「Date」「Category」などのファセットが表示されます。
solrconfig.xmlの該当箇所
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="df">body</str>
<str name="q.op">OR</str>
<str name="defType">edismax</str>
<str name="qf">title^5 title_2g body^3 body_2g body_reading</str>
<str name="mm">100%</str>
<str name="q.alt">*:*</str>
<str name="facet">on</str>
<str name="facet.field">category</str>
<str name="facet.field">ner_PERSON</str>
<str name="facet.field">ner_ORGANIZATION</str>
<str name="facet.field">ner_TITLE</str>
<str name="facet.field">ner_EVENT</str>
<str name="facet.field">ner_LOCATION</str>
<str name="facet.field">ner_LANGUAGE</str>
<bool name="hl">true</bool>
<bool name="hl.usePhraseHighlighter">true</bool>
<bool name="hl.highlightMultiTerm">true</bool>
<int name="hl.snippets">3</int>
<str name="hl.fl">title,title_2g,body,body_2g,body_reading</str>
<bool name="hl.requireFieldMatch">true</bool>
<str name="f.title.hl.alternateField">title</str>
<str name="f.body.hl.alternateField">body</str>
<int name="f.body.hl.maxAlternateFieldLength">100</int>
</lst>
<lst name="appends">
<str name="facet.query">date:[2000-01-01T00:00:00Z TO 2004-12-31T23:59:59Z]</str>
<str name="facet.query">date:[2005-01-01T00:00:00Z TO 2009-12-31T23:59:59Z]</str>
<str name="facet.query">date:[2010-01-01T00:00:00Z TO 2014-12-31T23:59:59Z]</str>
</lst>
</requestHandler>
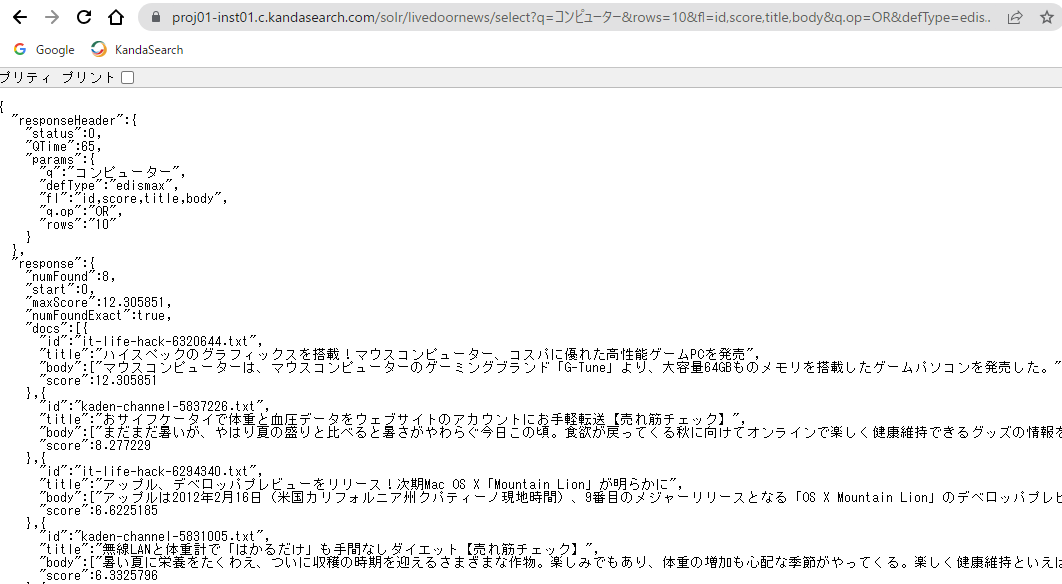
「JSONを表示する」では、検索レスポンス内にどのようにファセットの情報が格納されているかを確認できます。また、下図は「SOLR URLを表示する」をクリックして、そのURLをChromeブラウザで表示させ、ブラウザ内で「facet」部分を表示させたものです。
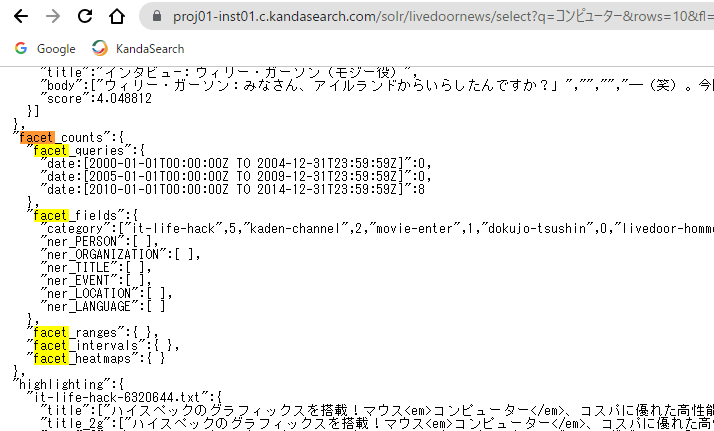
ハイライト
ハイライトとは、検索キーワードにヒットした文書における、当該検索キーワードを中に含む前後の部分文字列(これをスニペットと呼びます)を切り出して、検索結果と共に返却する機能です。
検索結果一覧にハイライトされたスニペットを表示することで、検索ユーザーは、求める文書を見つけやすくなります。
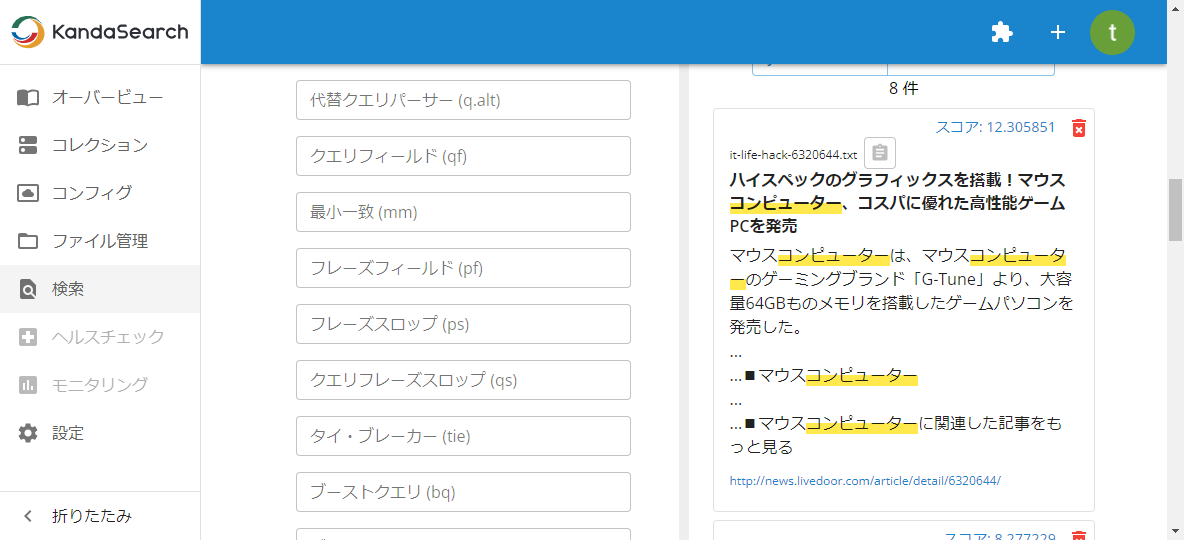
JSON形式のレスポンス内のスニペット部分を見ると、検索キーワードがHTMLタグで強調表示されていることを確認できます。
検索エンジンのハイライト機能は、レスポンスを受け取ったクライアント側でハイライト処理を行うよりも、以下の点で優位性があります。
- スニペットを切り出すロジックを書く必要がありません。
- 類義語等、表記揺れを考慮したハイライトが行えます。
- ネットワーク負荷を低減できます(特に1文書のサイズが大きい場合)。
livedoorニュースコーパスのコンフィグでは、デフォルトでハイライトが機能するように設定されています。
solrconfig.xmlの該当箇所の一部
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="df">body</str>
<str name="q.op">OR</str>
<str name="defType">edismax</str>
<str name="qf">title^5 title_2g body^3 body_2g body_reading</str>
<str name="mm">100%</str>
<str name="q.alt">*:*</str>
<str name="facet">on</str>
<str name="facet.field">category</str>
<str name="facet.field">ner_PERSON</str>
<str name="facet.field">ner_ORGANIZATION</str>
<str name="facet.field">ner_TITLE</str>
<str name="facet.field">ner_EVENT</str>
<str name="facet.field">ner_LOCATION</str>
<str name="facet.field">ner_LANGUAGE</str>
<bool name="hl">true</bool>
<bool name="hl.usePhraseHighlighter">true</bool>
<bool name="hl.highlightMultiTerm">true</bool>
<int name="hl.snippets">3</int>
<str name="hl.fl">title,title_2g,body,body_2g,body_reading</str>
<bool name="hl.requireFieldMatch">true</bool>
<str name="f.title.hl.alternateField">title</str>
<str name="f.body.hl.alternateField">body</str>
<int name="f.body.hl.maxAlternateFieldLength">100</int>
</lst>
Solr Adminを使う
Apache Solrを自前のサーバーにインストールして利用する場合、コントロールパネル的に利用するUIツールが「Solr Admin」です。 KandaSearchでも、Solr Adminを利用可能です。
「検索エンジンの作成」の章で説明した方法でSolr Adminを表示し、検索してみましょう。
左サイドの「Core Selector」から「livedoornews」を選択し、同じく左サイドの「Query」をクリック後、右側の検索条件の最下部にある「Execute Query」をクリックします。
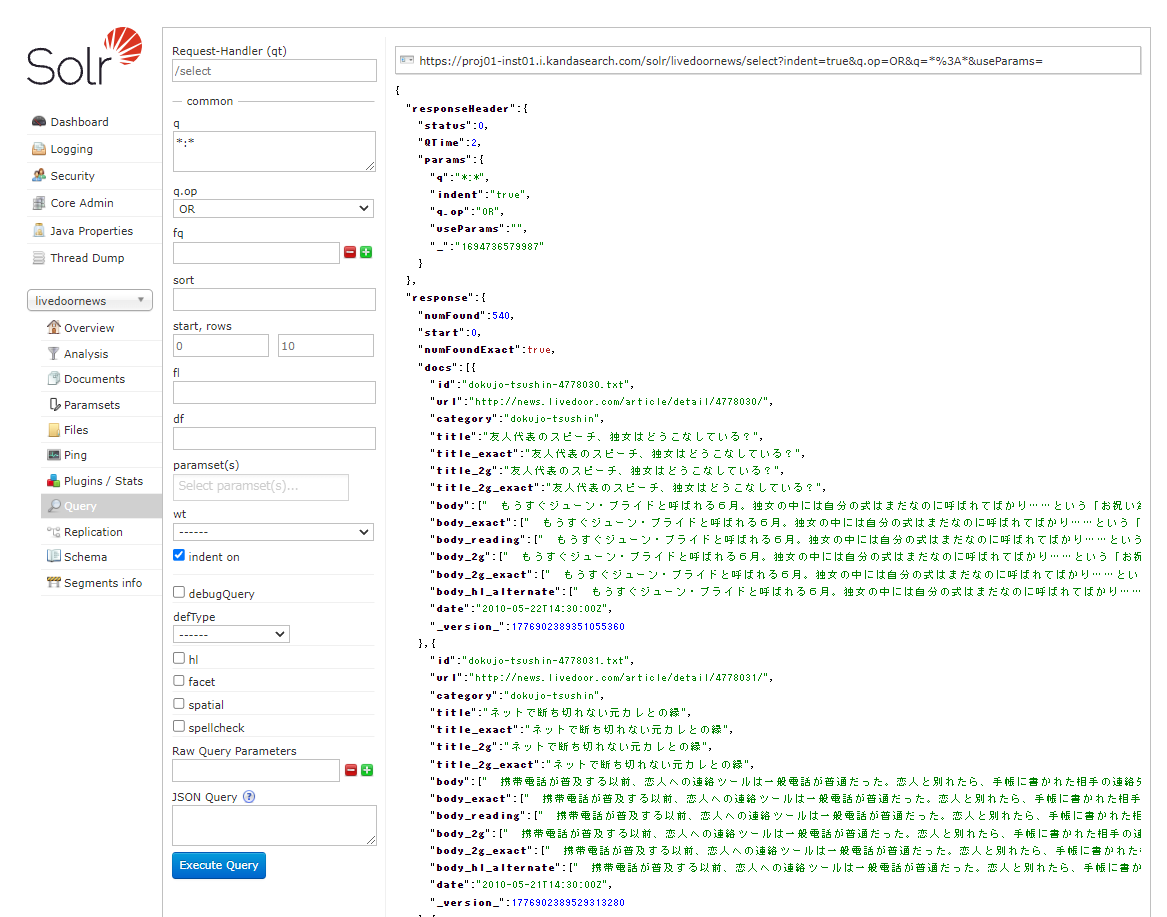
Solr Admin UIでは、KandaSearchの検索UIではサポートしていないグループ化検索や、検索のより細かい指定が可能です。
一方、KandaSearchの検索画面は標準でよく使われる基本パラメーターを厳選してサポートしています。そして、検索結果はファセットやハイライトも含めて見やすく成形表示されます。また、前述したように、クエリを保存してプロジェクトメンバー間で共有することが可能です。さらに後述するように、クエリサジェスチョンをリアルタイムに実行して動作を確認できます。
KandaSearchの検索UIを使って、開発するWebアプリケーションの検索機能のイメージをプロジェクトチームで共有しながらすばやく開発を進め、KandaSearchの検索UIでサポートされていない検索機能(Solrの検索パラメーター)の動作確認だけはSolr Admin UIを使うなど、目的に応じて両者を使い分けると、Webアプリケーション開発を効率的に進められるでしょう。
類義語辞書を使う
全文検索の性能評価の指標として「再現率(recall)」と「適合率(precision)」があります。
再現率は「検索漏れがどれだけ少ないか」を表し、適合率は「誤った検索結果(ノイズ)がどれだけ少ないか」を表します。
このうち、再現率を上げるために有効な手段が類義語(シノニム)辞書の利用です。
検索キーワードに「スマホ」を指定して検索したとき、「スマートフォン」が含まれる文書も検索結果に表示させたいケースで考えてみます。
「Livedoorニュースコーパス(mini)」データファイルを使ったコレクション「livedoornews」で、「スマホ」と「スマートフォン」のそれぞれで検索を行い、これらのキーワードを含む文書が存在することを確認しておきます。
「スマホ」では54件、「スマートフォン」では90件が該当します。
最初に類義語辞書の設定を行います。
類義語辞書はプロジェクトレベルの管理となっていますので、プロジェクトビューの左サイドから「類義語辞書」を選び、類義語辞書画面内の「辞書を追加する」ボタンをクリックします。
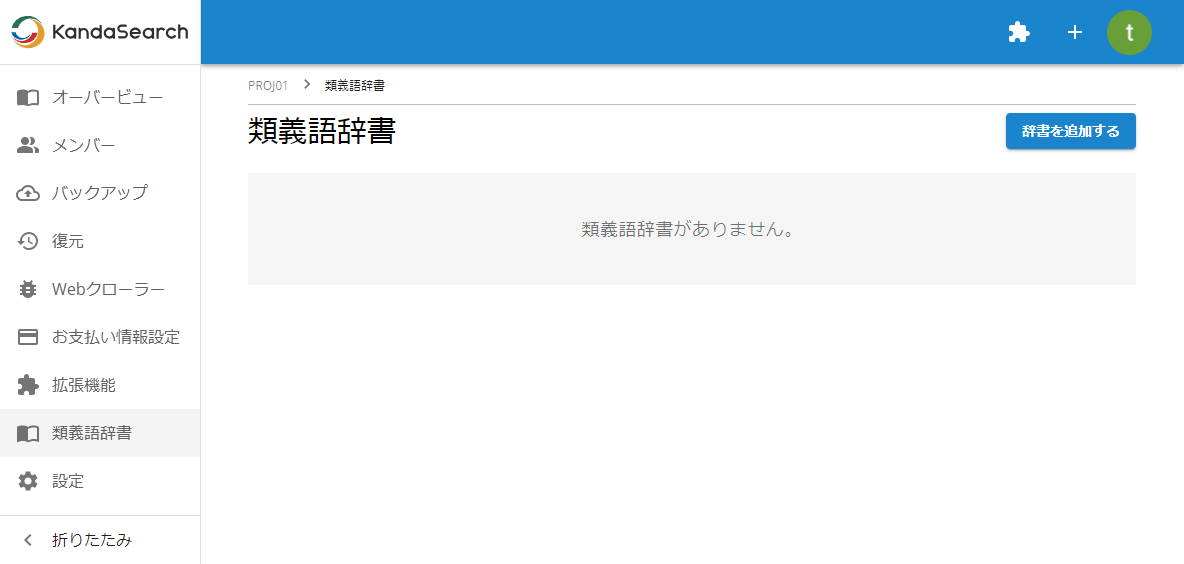
新規作成タブが選ばれている状態で任意の名前(ここではmydicとします)を指定し、「作成」をクリックします。
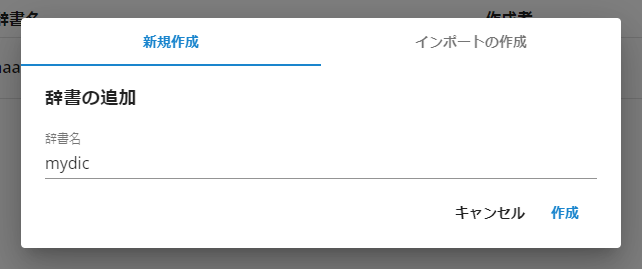
類義語一覧の mydic の行にある「辞書を見る」アイコン(アイコンにマウスを合わせると機能名が表示されます)をクリックし、「類義語セットを追加する」をクリックします。
「新しい単語」欄に「スマホ」と入力後、「+(クリックして追加)」アイコンをクリックします。
続けて、「新しい単語」欄に「スマートフォン」と入力後、「+(クリックして追加)」アイコンをクリックし、最後に「確認」をクリックすると類義語セットが登録されます。コメント欄は省略できます。
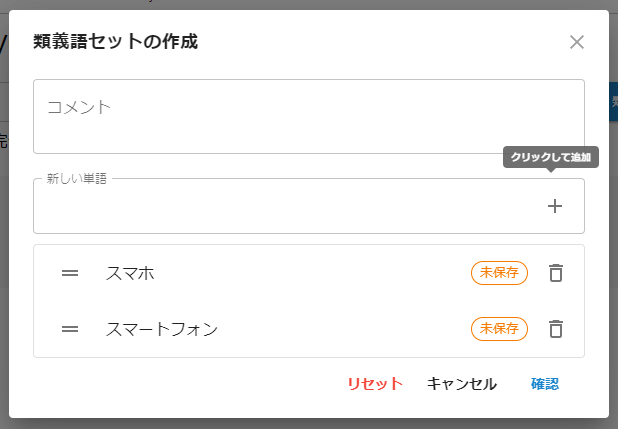
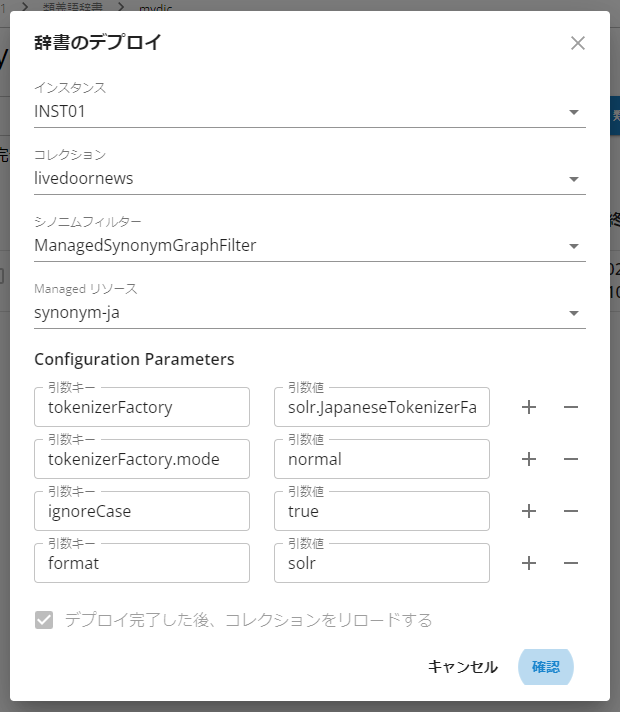
類義語セットの登録が完了したら、類義語辞書のデプロイを行うため、歯車のアイコンから「辞書をデプロイする」を選びます。
類義語セットの編集後は、必ずこのデプロイ操作を行ってください。
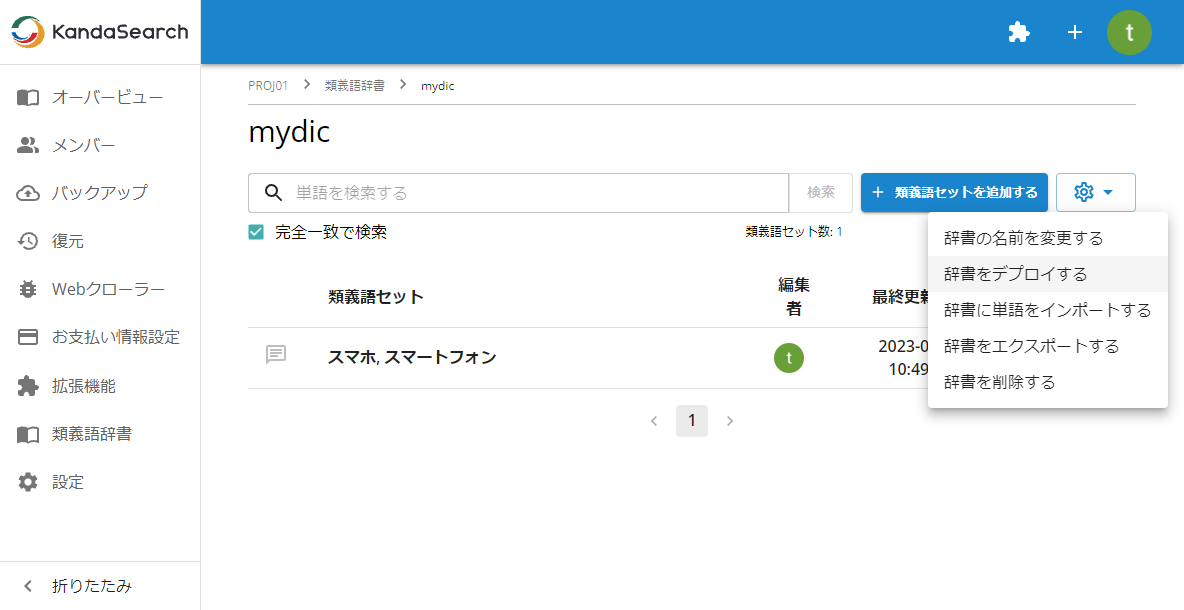
「辞書のデプロイ」画面で次の項目を指定します。
- インスタンス livedoornesコレクションのインスタンス
- コレクション livedoornews
- シノニムフィルター ManagedSynonymGraphFilter
- Managed リソース synonym-ja
- パラメーター
- tokenizerFactory solr.JapaneseTokenizerFactory
- tokenizerFactory.mode normal
- ignoreCase true
- format solr
以上を指定後、「確認」をクリックすると、デプロイとコレクションのリロードが行われ、類義語辞書の利用ができるようになります。
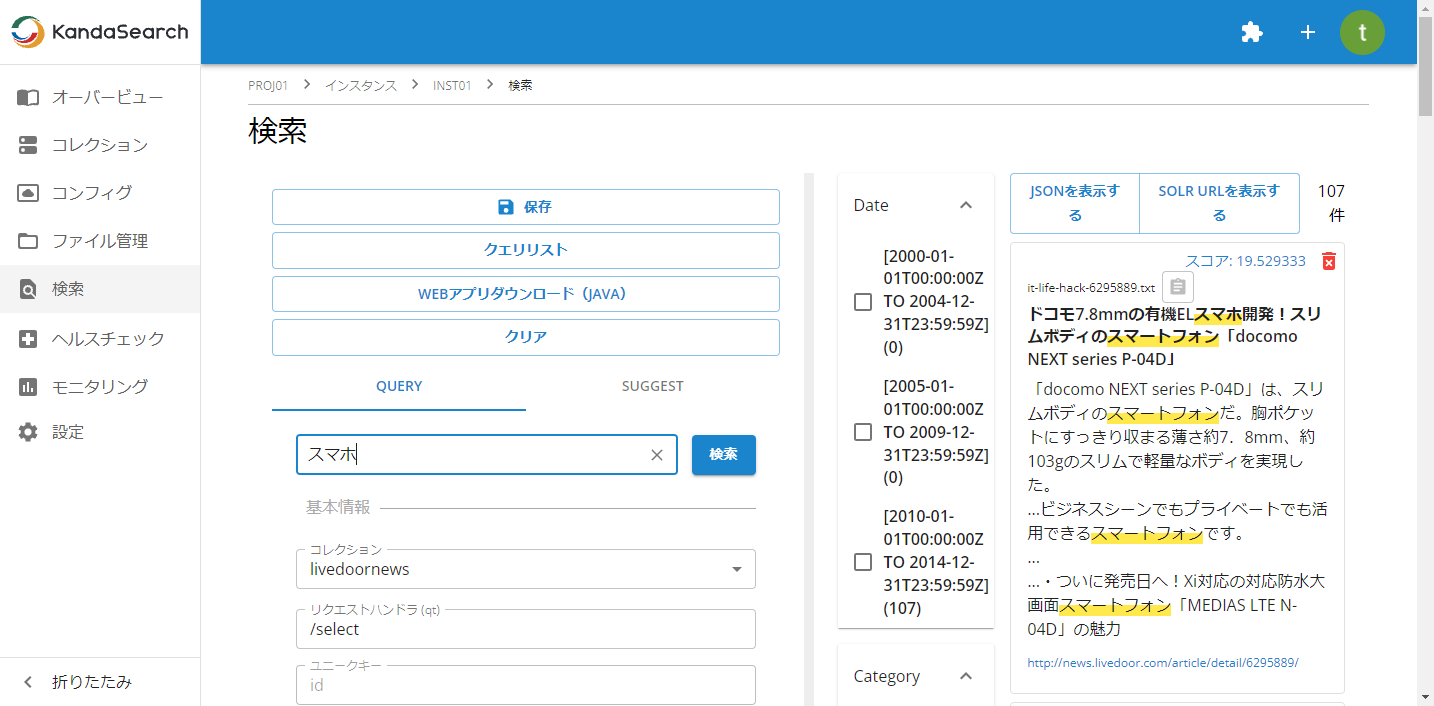
それでは、有効になった類義語辞書を使って検索してみましょう。
インスタンスビューの「検索」から前述の操作で保存したクエリを呼び出し、「検索キーワード」欄に「スマホ」や「スマートフォン」と入力して検索し、相互ヒットすることを確認します。
クエリサジェスチョン
検索サイトで検索キーワードを入力する際、数文字を入力し始めたときに、キーワードを提案(サジェスト)してくれる場面に遭遇する場合があると思います。この機能を「クエリサジェスチョン」といいます。別名「オートコンプリート」などとも呼ばれ、検索キーワード入力を補完することで、検索を便利にする目的として機能提供されるようになりました。
このクエリサジェスチョンは、検索エンジンでは SuggestComponent を使って実現できます。
ここでは、KandaSearchの拡張機能ライブラリーで提供している「RONDHUIT Suggest configuration(Solr 9)」を使い、設定や動作確認、クエリサジェスチョン実装時のポイントについて説明します。
サジェスト用のコレクションを追加する
最初に、KandaSearch画面の上部にある「拡張機能ライブラリー(ジグソーパズルの形)」アイコンをクリックし、拡張機能ライブラリーから「RONDHUIT Suggest configuration(Solr 9)」をプロジェクトに追加します。追加時はSolrのバージョン(今回はSolr9用)と追加先のプロジェクトの選択に注意してください。
追加先プロジェクトのプロジェクトビューへ移動し、左サイドの「拡張機能」をクリックし、表示された「RONDHUIT Suggest configuration(Solr 9)」ブロック内の「ダウンロード」をクリックして、最新版のコンフィグファイルをパソコンへダウンロードします。
インスタンスビューの左サイドの「コレクション」を選択し、「+コレクション追加する」をクリックします。
「インポートによる作成」タブでダウンロードしたコンフィグファイルとコレクション名(ここではsuggest9とします)を指定して「保存」をクリックします。
コレクションへサジェストデータソースを登録する
サジェストの動作確認を行う前に、この suggest9 コレクション内にドキュメント(サジェストデータソース)を登録しておく必要があります。サジェスト時に表示されるテキストです。
クエリサジェスチョンの一番のポイントは、設定(コンフィグ)もさることながら、 何をサジェストするか? です。
たとえば、書籍の検索システムであれば、書籍のタイトルや著者名などがサジェストデータソースとして登録されていれば、ユーザーには便利かもしれません。
また、その検索システムでよく指定されるキーワードをサジェストするために、solr.log に記録されている、過去の検索キーワードをサジェストデータソースとして用いることもよく行われます。
ここで、注意しなければならない点として、「システムがサジェストしたからには、ヒット0件となってはならない」ということがあげられます。ですので、solr.log からサジェストデータソースを抽出する場合、ヒット件数(solr.log に検索キーワードと共にヒット件数が記録されています)が1件以上のものをサジェストデータとして使用するといった工夫が必要になります。
また、ドキュメントや solr.log の更新により、定期的にサジェストデータソースのアップデートが必要になる場合もあります。
このチュートリアルでは、検索対象のドキュメントやsolr.logから抽出するのではなく、Terms Component (https://solr.apache.org/guide/solr/latest/query-guide/terms-component.html)を使って、適当なフィールド(今回はbody)から、上位1000件の単語一覧を取得して、これをサジェスト用に作成したコレクション(ここではsuggest9)の suggest フィールドに登録し、クエリサジェスチョンの挙動を確認します。この方式でも、当該単語は必ず body フィールドに存在するので、ヒット0件となることはないというわけです。
Terms Component 機能を用いた以下のようなURLへブラウザよりアクセスし、livedoornewsインデックス(miniの方)から、bodyフィールド内の単語の(出現)上位1000件をjson形式で取得してみます。
結果が正常に表示されない場合は、URLが正しいことやインスタンスに対する許可IPの設定を確認してください。
また、URL内のインスタンスのサブドメインやプロジェクト名、インスタンス名、コレクション名は、ご利用の環境に合わせて読み替えてください。
https://proj01-inst01.c.kandasearch.com/solr/livedoornews/terms?terms=true&terms.fl=body&terms.limit=1000&terms.sort=count&wt=json
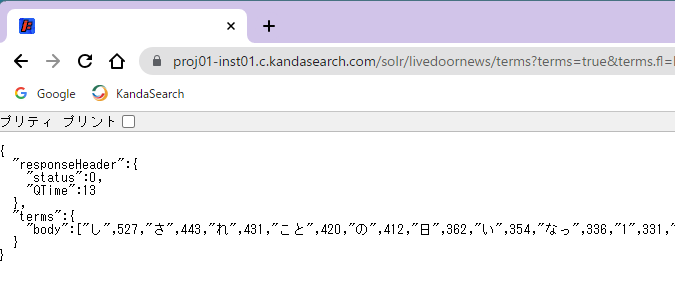
ここで取得したレスポンスを元に、サジェスト用コレクション(ここではsuggest9)へのドキュメント登録に使用するためのCSVファイルを作成します。
ここでのサジェスト用のフィールドは、インスタンスビューの左サイドメニューの「コンフィグ」の managed-schema.xml で確認できます。
<field name="point" type="int" sortMissingLast="true" indexed="true" stored="true"/>
<field name="suggest" type="string" indexed="true" required="true" stored="true"/>
上記のpointフィールドは、サジェストキーワードの重要度を示します。
上述のTerms Component 機能を使用して取得したデータには、「単語」と「その単語にマッチする文書の数」がセットで格納されています。ここでは、pointフィールドに設定するデータとして、Terms Componentで返された「その単語にマッチする文書の数」を使用することに妥当性があると思われますので、point と suggest を使って以下のようなCSV形式でファイルを作成します。
CSVファイルの文字コードはUTF-8であることに注意してください。
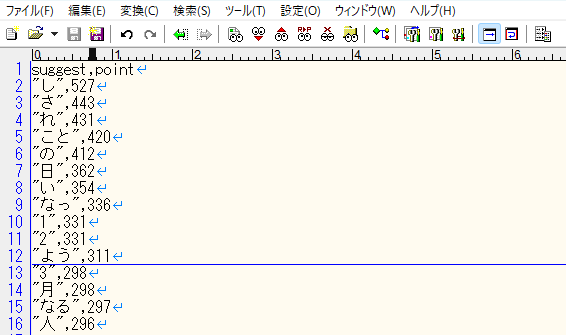
このCSVファイルをサジェスト用コレクション(ここではsuggest9)のドキュメントとして登録します。
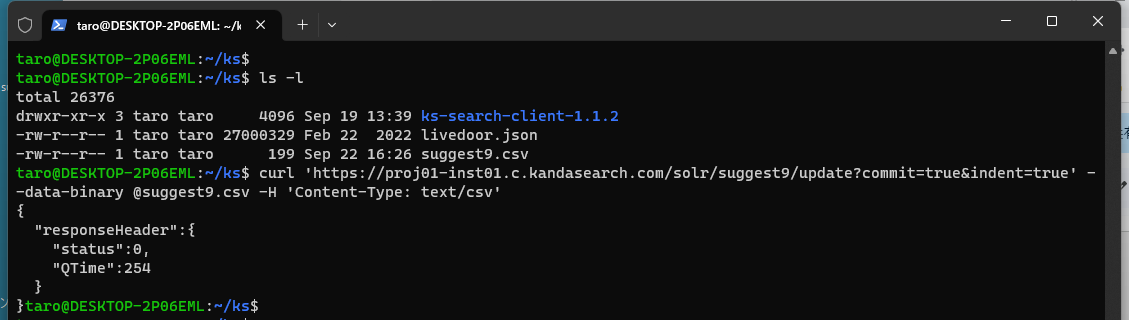
作成したファイルを、Macのターミナルや、WindowsパソコンのWSL(Windows Subsystem for Linux)から参照可能な場所にコピー後、ターミナルから次のようなcurlコマンドを実行します。
curl -X POST 'https://proj01-inst01.c.kandasearch.com/solr/suggest9/update?commit=true&indent=true' --data-binary @suggest9.csv -H 'Content-Type: text/csv'
念のため、サジェスト用コレクションに上述のドキュメントが登録されていることを、インスタンスビューの「検索」画面から確認します。
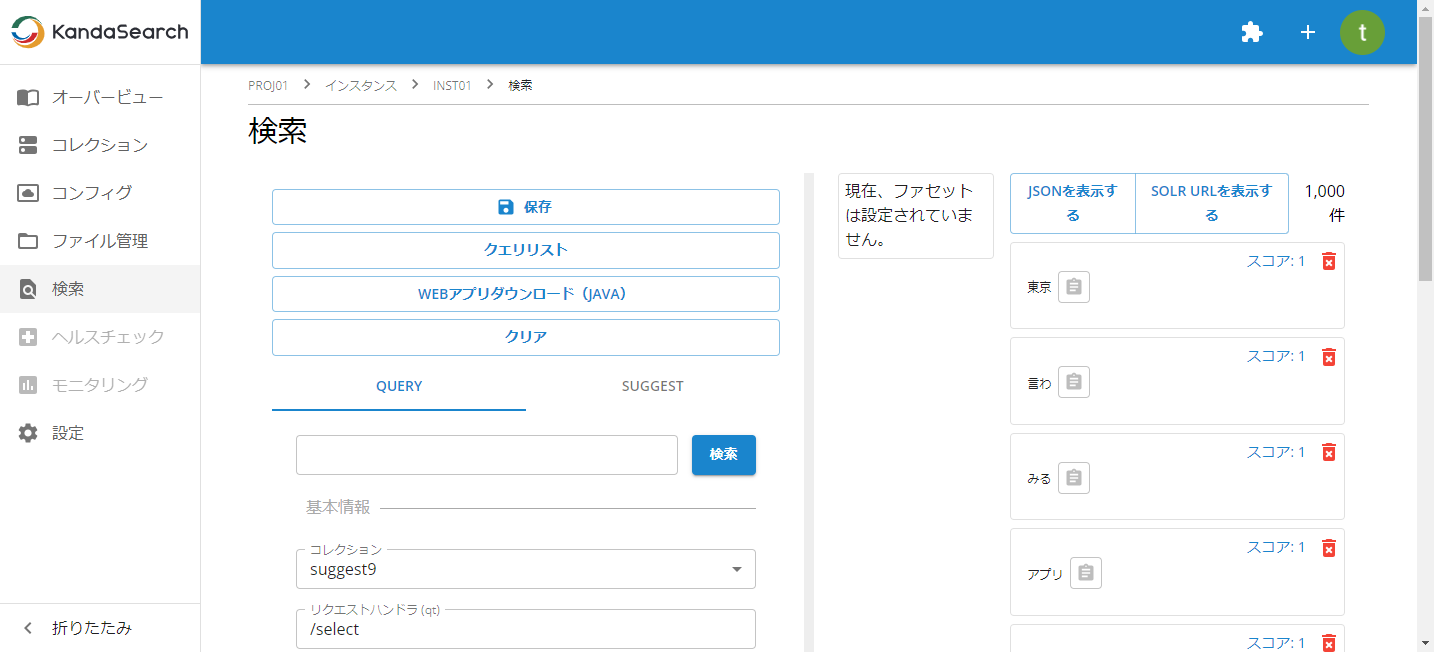
うまく登録できているようです。
サジェストを試す
それでは、サジェスト機能を試してみましょう。
KandaSearchのインスタンスビューの左サイドの「検索」を選択します。
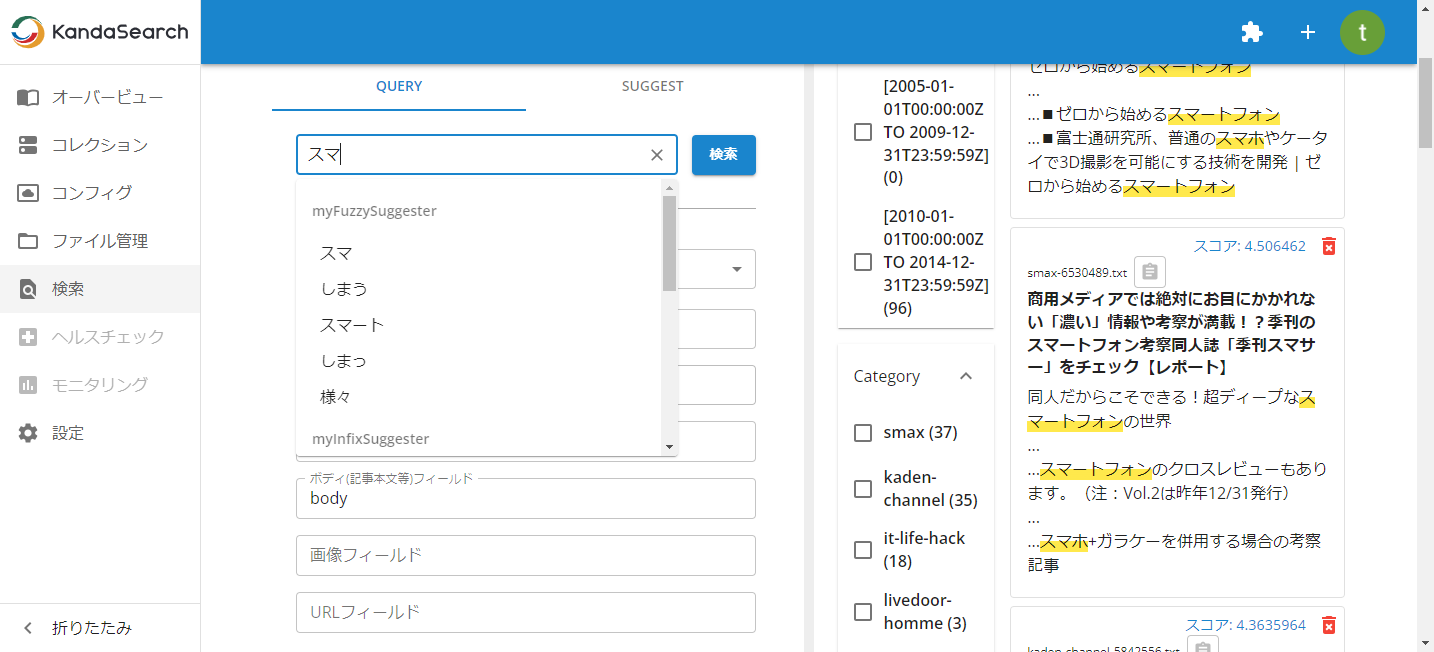
検索画面の左ペインで「SUGGEST」タブを選択し、コレクションに「suggest9」、リクエストハンドラに「/suggest」を指定します。辞書にはmyFuzzySuggester、myInfixSuggester、mySolrSuggester、mySuggesterを指定可能です。(カンマ区切りで複数の辞書を指定可能です)
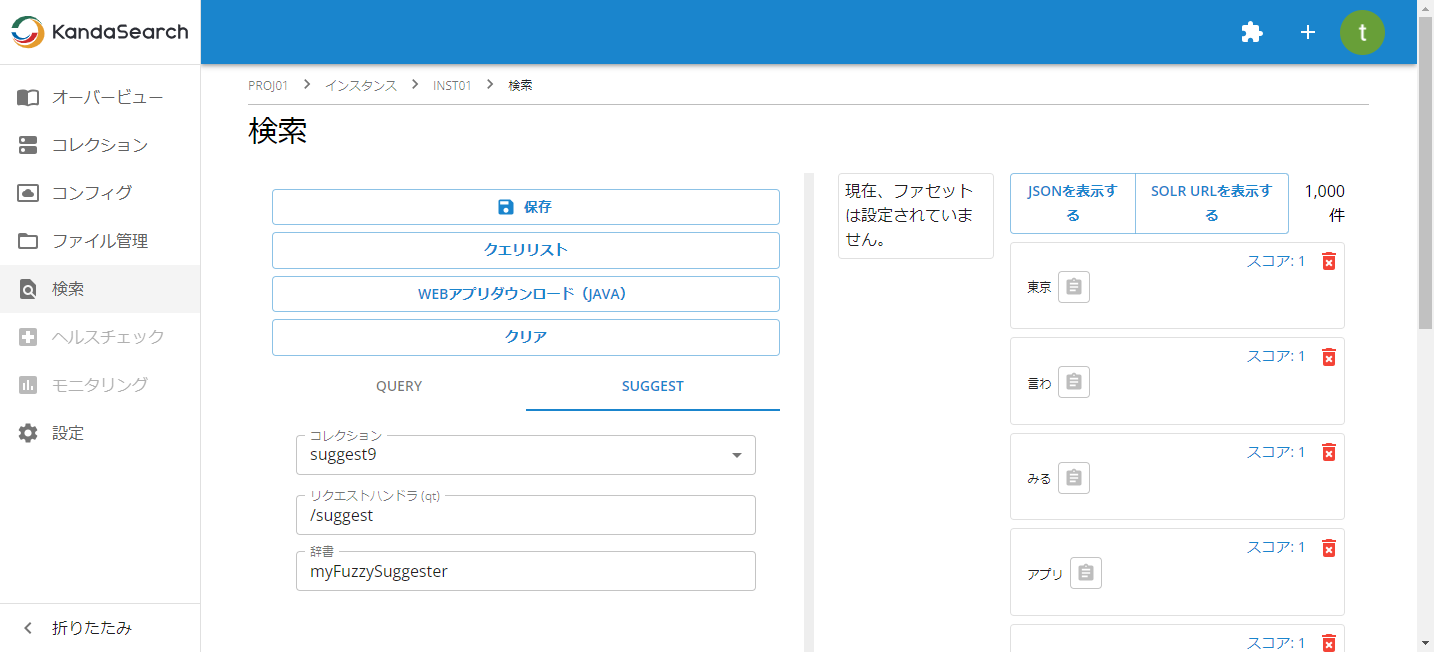
上記の「SUGGEST」タブ設定はそのままにして、次は「QUERY」タブをクリックし、キーワード入力欄に、「スマ」と入力してみましょう。
以下のようにサジェストが表示され、クエリサジェスチョンが機能していることを確認できます。