
TUTORIAL チュートリアル
06. WebApp開発
このページの項目
前の章でKandaSearchの検索UIを使って検索できることを確認しました。
現実的には、利用者が検索操作を行うための、検索Webアプリケーションの作成が必要になります。
ここでは検索Webアプリケーションから利用する検索エンジンのAPIなどについて説明します。
検索API
KandaSearchに作成した検索エンジンをインターネット側から利用するにはSolr APIを使用します。
MacのターミナルやWindowsのターミナルのWSLから curlコマンド を使って検索APIを試してみましょう。
ブラウザから、インスタンスビューの左サイドの「検索」をクリックし、表示された検索画面の左ペインで、コレクション欄に「livedoornews」を指定して検索します。 検索結果が表示されたら、右ペイン上部の「SOLR URLを表示する」をクリックし、リクエストURLをクリップボードにコピーします。
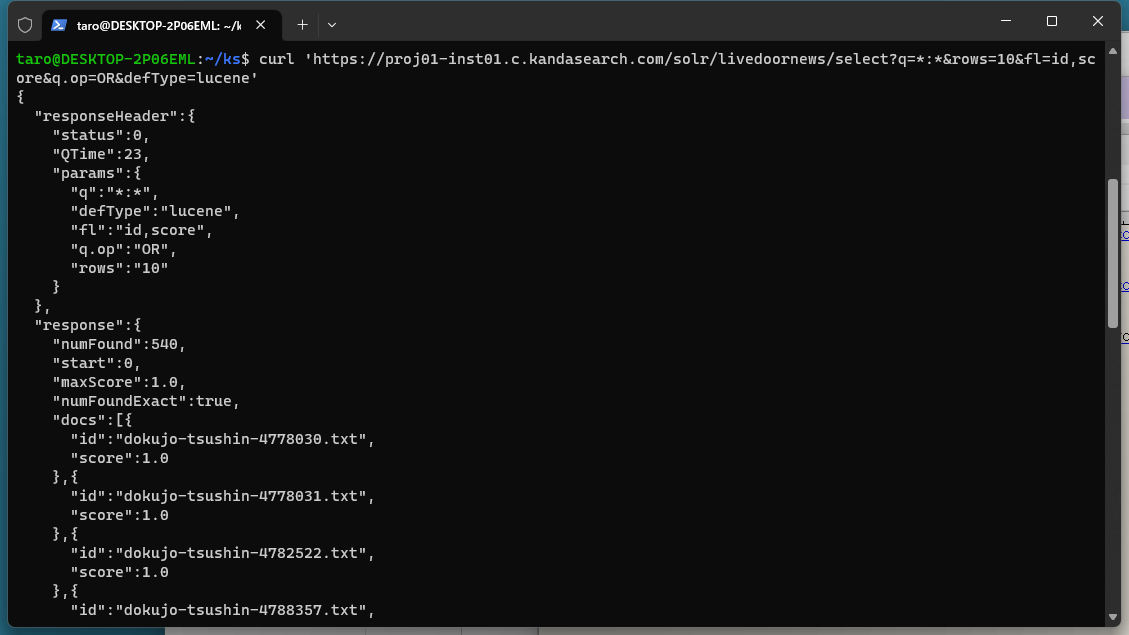
以下のように、コピーしたURLを指定して curl コマンドを実行すると、レスポンスが表示されます。
結果が正常に表示されない場合は、ターミナル内に入力したコマンドが正しいことやインスタンスに対する許可IPの設定を確認してください。
また、URL内のインスタンスのサブドメインやプロジェクト名、コレクション名は、ご利用の環境に合わせて読み替えてください。
curl 'https://proj01-inst01.c.kandasearch.com/solr/livedoornews/select?q=*:*&rows=10&fl=id,score&q.op=OR&defType=lucene'
今度は、KandaSearchの検索画面で、
- キーワード コンピューター
- コレクション livedoornews
- タイトルフィールド title
- ボディフィールド body
- URLフィールド URL
- クエリパーサー edismax
を、指定して「検索」をクリックします。
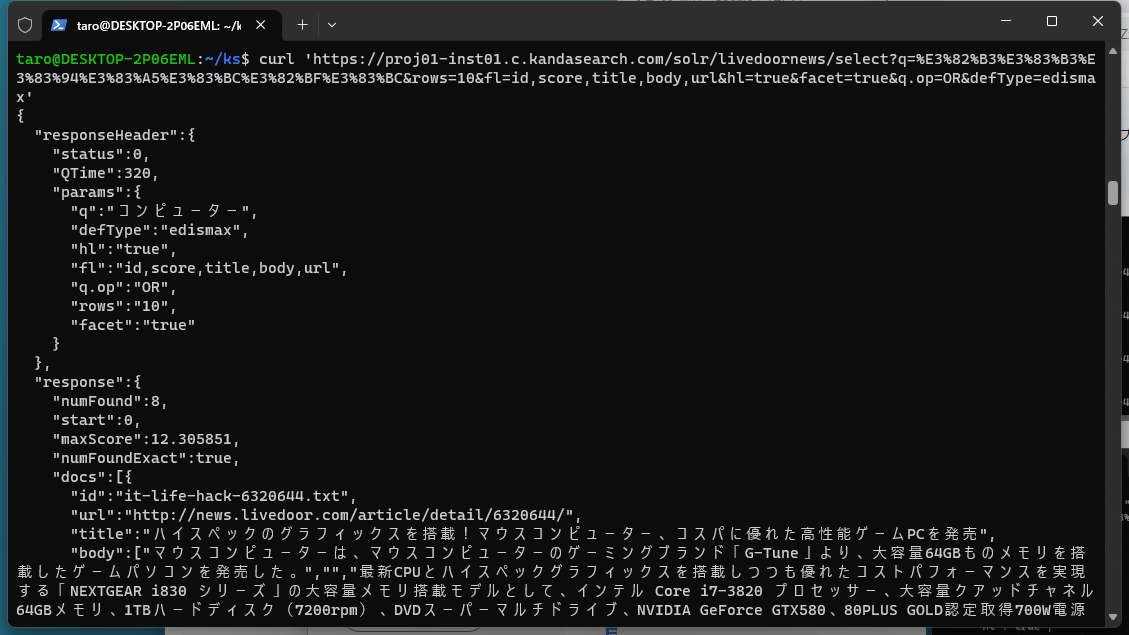
先ほどと同様に「SOLR URLを表示する」をクリックし、クリップボードにコピーしたURLを用いて、ターミナルウィンドウから curl コマンドを実行します。
以前の章での説明の通り、livedoornewsコレクションでは、デフォルトでハイライトとファセットがオンになっていますので、レスポンスにハイライトやファセットの情報が含まれていることを確認できます。
curl 'https://proj01-inst01.c.kandasearch.com/solr/livedoornews/select?q=%E3%82%B3%E3%83%B3%E3%83%94%E3%83%A5%E3%83%BC%E3%82%BF%E3%83%BC&rows=10&fl=id,score,title,body,url&hl=true&facet=true&q.op=OR&defType=edismax'
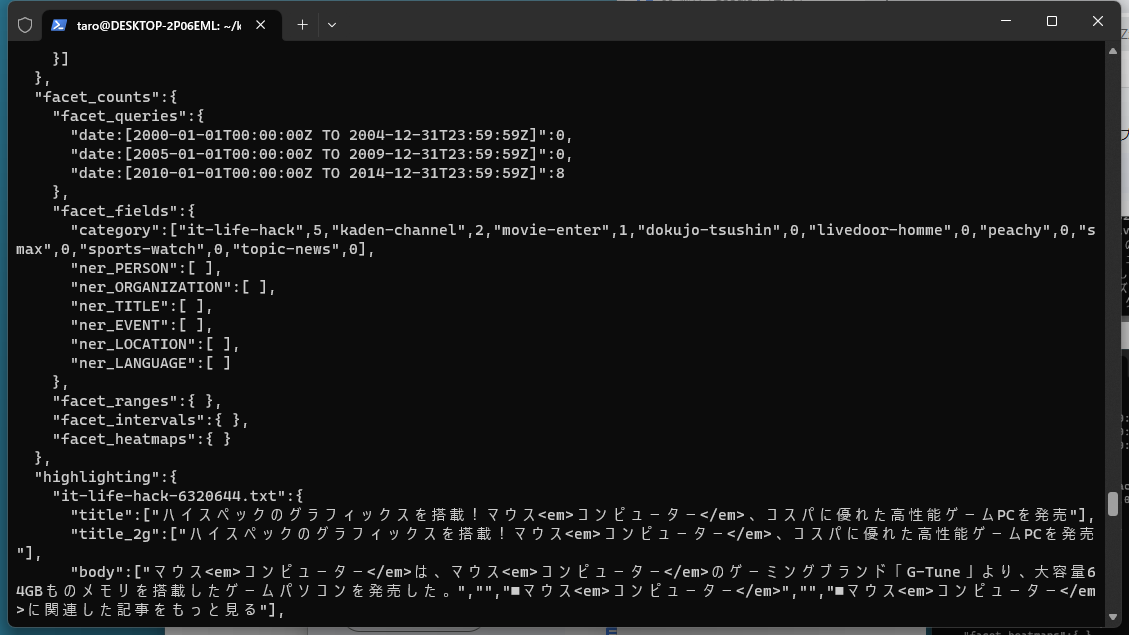
Apache Solrの検索 APIの詳細については、Apache Solr Reference GuideのQuery Guideに詳しく説明されていますが、ここでは基本的な検索パラメーターをご紹介します。
基本的な検索パラメーター
q
検索キーワードを指定します。以下に例を示します。
# 「コンピューター」を検索
q=コンピューター
# 「コンピューター」または「サーバー」を検索
q=コンピューター OR サーバー
# 「コンピューター」かつ「サーバー」を検索
q=コンピューター AND サーバー
# 「コンピューター」を含むが「サーバー」を含まない検索
q=コンピューター NOT サーバー
# 「コンピューター」または「サーバー」を含み、かつ「インターネット」を含む検索
q=(コンピューター OR サーバー) AND インターネット
特定のフィールド名のみを検索する場合、コロン : を使って次のように検索します。
# titleフィールドだけを検索
q=title:コンピューター
# 前述の検索式とフィールド名指定を組み合わせることも可能
q=title:コンピューター OR body:サーバー
# 全件検索
q=*:*
なお、フィールド名は設定ファイルの一種である managed-schema.xml というXMLファイルでスキーマ設定されており、KandaSearch UIのコンフィグやファイル管理から参照や変更が可能です(変更した場合はコレクションのリロードを行って変更を有効化します)。
fl
検索結果として返却するフィールド名をカンマ区切りで次のように指定します。
fl=id,title,body,score
なお、flパラメーターにフィールド名を指定するには、当該フィールドが managed-schema.xml で stored=true として設定されていなければなりません。
また、上の例で指定されているフィールド score はスコア(前述のクエリと文書の関連度)を表す特殊フィールドです。flに score を指定することで、当該文書のスコアを取得することができます。
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="title" type="text_ja" indexed="true" stored="true"/>
<field name="body" type="text_ja" indexed="true" stored="true" multiValued="true"/>
なお、flパラメーターを指定しない場合のデフォルトは、「すべての stored=true のフィールドを返す」となります。Webアプリケーションにて使用(表示)しないフィールドを要求するのは、ネットワークトラフィックの負荷を高めることになるので、flパラメーターは必要なフィールド名を指定するのがお勧めです。
rows と start
rowsパラメーターで「検索結果として一度に返却する文書数」を指定します。デフォルトは10です。startパラメーターは「検索結果として返却する文書リストのうち、何件目から返却するか」を指定します。デフォルトは0(リストの最初から返却する)です。この2つのパラメータを組み合わせることで、検索結果リスト表示のページ送り(ページ戻し)機能をWebアプリケーションに実装できます。
# 検索結果リストの最初の10件を表示
rows=10&start=0
# 検索結果リストの「次の10件(2ページ目)」を表示
rows=10&start=10
# 検索結果リストの「さらに次の10件(3ページ目)」を表示
rows=10&start=20
上記は1ページあたり10件とした場合ですが、1ページあたり20件の場合は次のようになります。
# 検索結果リストの最初の20件を表示
rows=20&start=0
# 検索結果リストの「次の20件(2ページ目)」を表示
rows=20&start=20
# 検索結果リストの「さらに次の20件(3ページ目)」を表示
rows=20&start=40
インデクシングAPI
次は、インデクシング関連のAPIについての説明です。
インデクシング
KandaSearchの画面を使ったインデクシングの方法は、「インデクシング」の章で説明を行っていますが、画面からの操作は手動での作業となり、また、アップロードできるドキュメントのサイズに上限があるなどの制約があります。
そこで、インデクシングにおいてもAPIを使うことは、アプリケーション実装時の一般的な手法となります。
MEMO:
インデクシング(ドキュメントの登録、更新、削除)を確定するためにはコミットが必要です。
それには、<commit />というXMLをPOSTするか、HTTPリクエストに commit=true というパラメーターを付与してAPIを実行します。
また、コミットは、solrconfig.xml に autocommit を設定することで、ドキュメント数や時間によって自動的に実行することもできます。
それでは、(KandaSearchの「ドキュメントを登録する」からはサイズ制限により登録できない)2Mバイトを超えるデータファイルをlivedoornewsコレクションにインデクシングしてみましょう。
最初に、拡張機能ライブラリーからmini版ではない方のlivedoorニュースコーパスデータをプロジェクトに追加し、パソコンへダウンロードします。
そのために、画面上部のジグソーパズルアイコンをクリックし、拡張機能ライブラリーから「Livedoorニュースコーパス」をプロジェクトに追加します。
プロジェクトビューへ移動し、左サイドの「拡張機能」を選択します。一覧から「Livedoorニュースコーパス」ブロック内の「ダウンロード」をクリックし、データをパソコンへダウンロードします。
ダウンロードしたZIPファイルを解凍し、ターミナルから参照可能なフォルダへJSONファイルをコピーします。
インデクシングの前に、以下のようなコマンドを使って、登録済みのドキュメントをすべて削除します(コミットオプションも指定します)。
URL内のインスタンスのサブドメインやプロジェクト名、コレクション名は、ご利用の環境に合わせて読み替えてください。(以下同様)
curl -X POST 'https://proj01-inst01.c.kandasearch.com/solr/livedoornews/update?commit=true' -H 'Content-type:text/json;charset=utf-8' --data-binary '{"delete":{"query":"*:*"}}'
このコマンドで送信しているJSONデータに注目します。
{
"delete":{
"query":"*:*"
}
}
KandaSearchの検索エンジンでは、上記のようなJSON表現で文書の削除を実行します。上記のdeleteの中に「削除対象とする文書を特定するためのクエリ」をqueryの値として表記します。上記では「全件検索(*:*)」が指定されているので、全文書削除が実行されます。
MEMO: 特定の文書、例えばidがdokujo-tsushin-4778030.txtの文書を削除するには、次のように指定します。
{
"delete":{
"query":"id:dokujo-tsushin-4778030.txt"
}
}
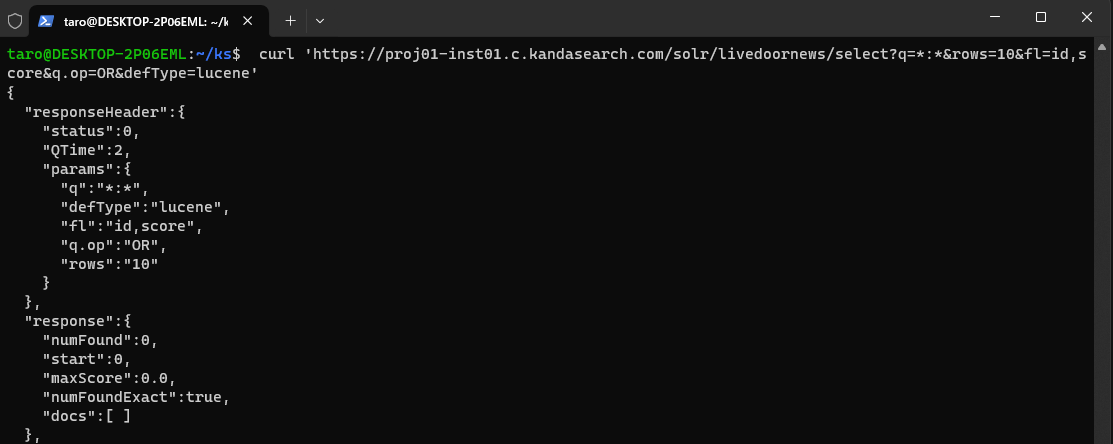
さて、全文書削除を実行したら、次のコマンドを実行してドキュメントがすべて削除されたことを確認("numFound":0 の部分です)します。
curl 'https://proj01-inst01.c.kandasearch.com/solr/livedoornews/select?q=*:*&rows=10&fl=id,score&q.op=OR&defType=lucene'
インデックスが空になっていることを確認したら、次のコマンドでインデクシングを行います。JSONファイル名は、livedoor.jsonとしています。
完了まで1分ほどかかる場合があります。
curl -X POST 'https://proj01-inst01.c.kandasearch.com/solr/livedoornews/update?commit=true&indent=true' --data-binary @livedoor.json -H 'Content-Type: text/json'
インデクシングが終わったら、上述の検索用のAPIを再度実行して、全7367件のドキュメントの登録ができていることを確認します。("numFound":7367 の部分です)
KandaSearchの検索画面からも確認してみましょう。
文書の更新
検索エンジンにおける文書の更新は、文書の新規登録とまったく同じです。
検索エンジンでは、文書の登録(または更新)は、内部的に以下のように実施されます。
- 登録(または更新)されようとしている文書のユニークキー(livedoorニュースであればidフィールドの値)で既存文書を検索
- 既存文書があれば削除する
- 登録(または更新)されようとしている文書を新規登録
上記のように実行されるため、検索エンジンにおける既存文書の内容更新は新規文書登録とまったく同じ作業となります。
MEMO: 定義が任意であるユニークキーについて、もしユニークキーが設定がされていない場合は上述のプロセスが実行できないため、文書の更新ができなくなってしまいます(したがって、ユニークキーは必ず設定するようにしましょう)。
WebAppダウンロード
WebAppとは
KandaSearch上に作成した検索エンジンにアクセスし検索結果を表示するには、ウェブサーバー上にウェブアプリケーションを用意するのが一般的です。これがWebAppです。
KandaSearchのインスタンスビューの「検索」画面では、左ペインの条件設定に応じて検索した時のクエリを含んだウェブアプリケーションとして動作するJavaクライアント(Spring Bootを利用)をダウンロードできます。
アプリケーション開発者は、このコードを元にアプリケーションからのアクセス手法を理解したり、デザインなどの調整を行ったりすることで、効率よくWebApp開発を進められます。
ここでは、MacのターミナルやWindowsパソコンのWSLへインストール済みのJavaを使って、ダウンロードしたWebAppをパソコンのブラウザから実行してみます。コレクションにはlivedoornewsを利用しています。
WebAppのダウンロード
インスタンスビューの左サイドの「検索」を選択し、これまでのチュートリアルで保存したクエリなど読み出すなどして検索を行います。
次に、左ペイン上部の「WEBアプリダウンロード(JAVA)」をクリックし、ダウンロードの完了を待ちます。(ダウンロードが完了するまで、ブラウザを閉じないでください。)
パソコンにダウンロードしたZIPファイルを解凍し、ターミナルからアクセス可能な任意のフォルダーへコピーします。 なお、解凍したフォルダ内の「README.md」に、ご利用にあたっての注意書きや使用方法などが記載されていますので事前にご一読ください。
WebAppの実行
ターミナルウィンドウへ移り、Linuxのコマンド操作で、Javaアプリケーションをコピーしたフォルダへカレントディレクトリを移動します。
以下のコマンドを実行します。
必要に応じて、jarファイル名はダウンロードしたファイル内の名前に読み替えてください。
また、パソコンの接続元IPアドレスが、インスタンスの許可IPに登録されているかどうかも確認しておきましょう。
java -jar ks-search-client-1.1.4.war
上図のターミナルウィンドウの表示はそのままにしておき、ブラウザのアドレス欄に以下のURLを入力して、パソコン上で稼働しているWebAppへアクセスします。
http://localhost:9090
WebAppが正常に動作した場合、WebAppからKandaSearchへ検索リクエストが送信され、WebAppは返ってきたレスポンスを成形し、以下のような画面を表示します。
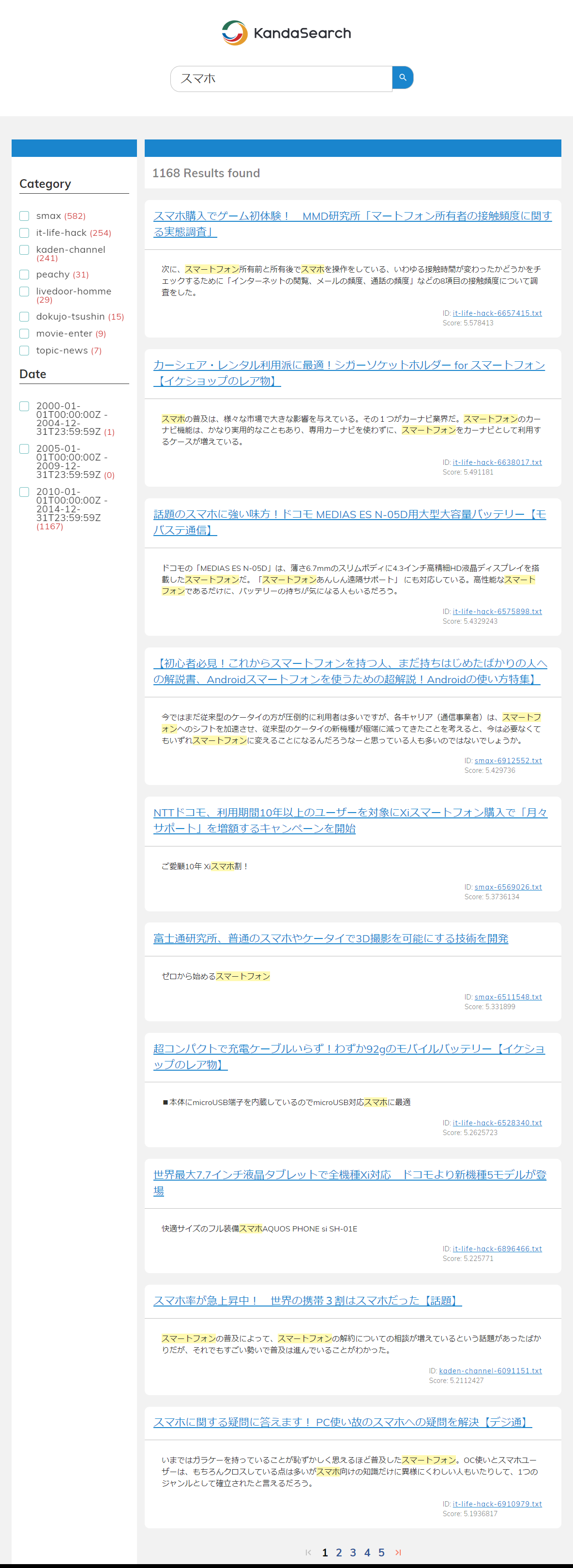
「Enter your search terms here」欄にキーワードを入力して、WebAppからKandaSearchの検索エンジンを使った検索ができるか試してみましょう。
JavaのWebAppを終了する場合は、ターミナルウィンドウ内で Ctrl+C を入力します。