
TUTORIAL チュートリアル
07. KandaSearchの運用機能
このページの項目
KandaSearchには、検索エンジンの運用を支援するための便利な機能がありますので、その一部をご紹介します。
各機能の詳細は、ドキュメントでご確認いただけます。
バックアップとリストア
インデックスや各種ファイルを手動または自動でバックアップできます。また、バックアップしたデータからのリストアも可能です。
バックアップとリストアは、プロジェクトの管理項目です。
バックアップで利用可能なストレージ容量はご利用プランにより異なります。料金プランページで、各プランの仕様をご確認ください。
バックアップ
バックアップについて説明します。
バックアップの方式には「今すぐ(手動)」と「定期(自動)」の2種類があります。
手動でバックアップを行うには、プロジェクトビューの左サイドから「バックアップ」を選択し、バックアップ画面の「今すぐバックアップを取る」をクリックします。
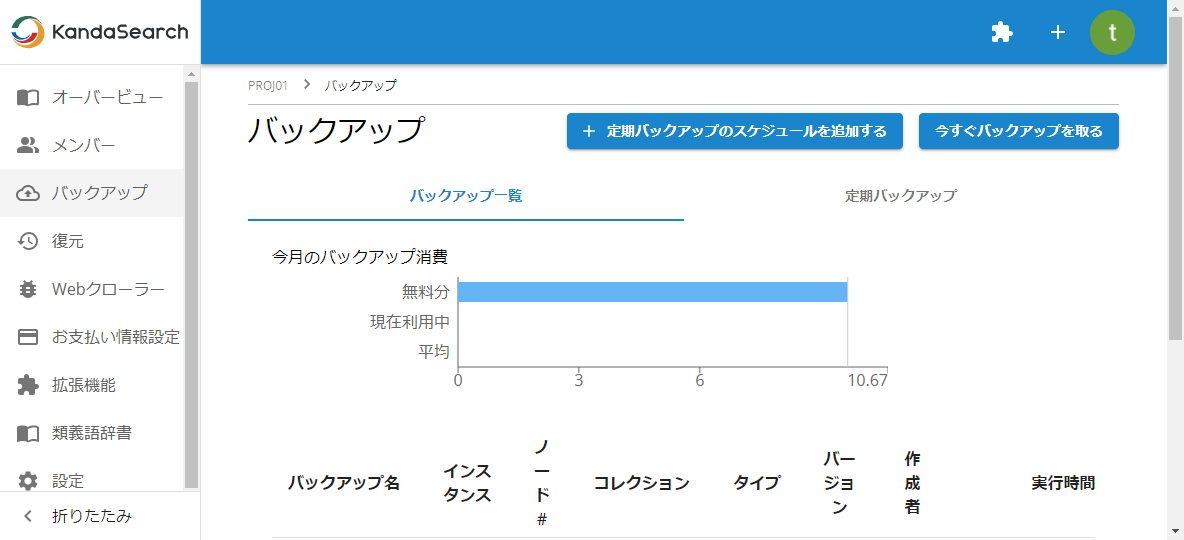
バックアップ名を指定し、インスタンスを選択します。
バックアップの種類で「インデックスバックアップ」を選択したときは、バックアップ対象のコレクションを選択します。
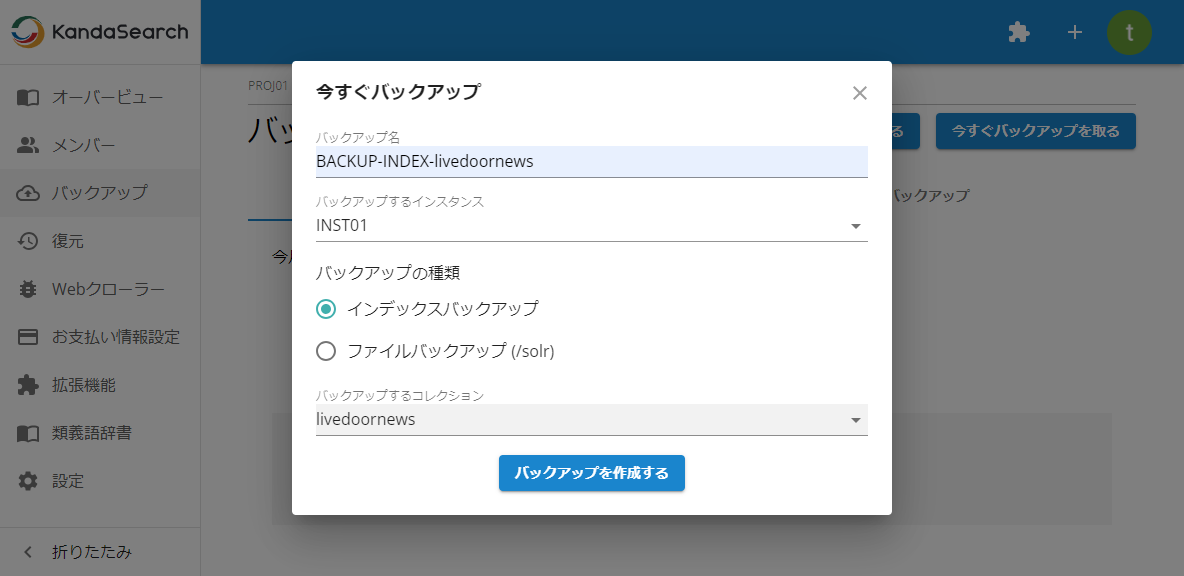
バックアップの種類で「ファイルバックアップ」を選択したときは、バックアップ対象のコレクションを選択した後、「含まれるファイル」「(含まれるファイルから)除外されたファイル」で、それぞれの対象ファイル名を指定します。指定後、必ず「プレビュー更新」をクリックしてください。
対象を絞り込むことでストレージの使用量を節約できます。
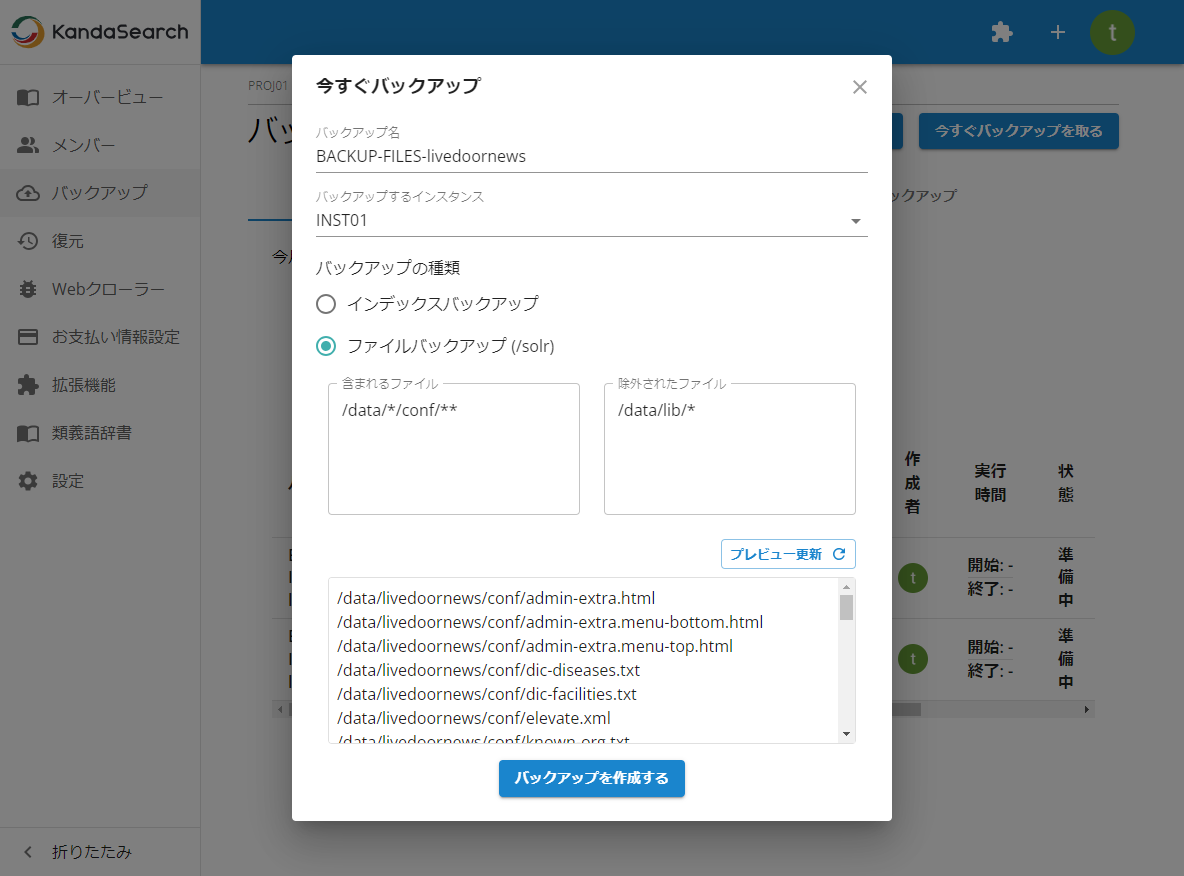
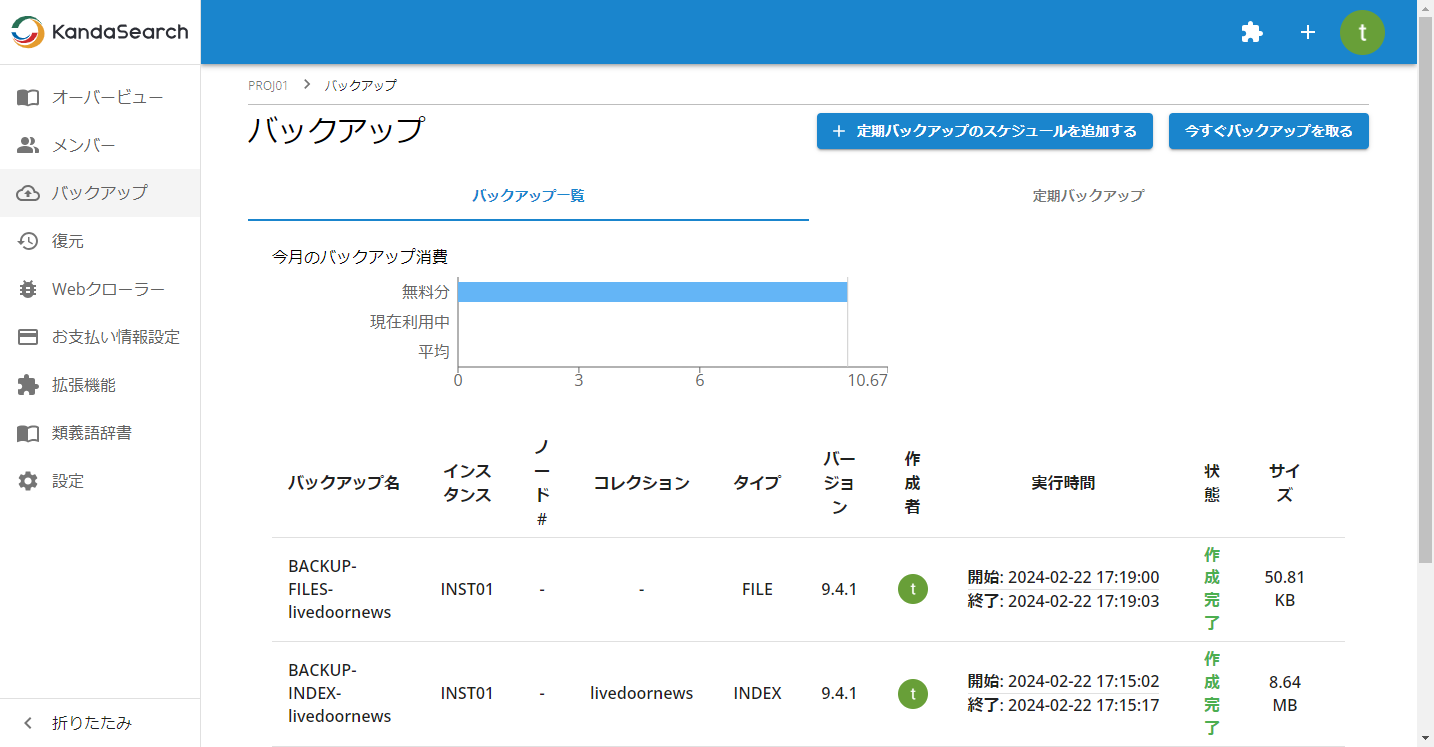
それぞれの指定が完了したら「バックアップを作成する」をクリックします。
バックアップ画面に、作成したバックアップジョブが表示され、状態などを確認できます。
定期的に自動でバックアップを取りたい場合は「定期バックアップのスケジュールを追加する」をクリックします。
前述の手動バックアップ時に指定する項目に加え、バックアップスケジュールとバックアップ保存数を指定します。
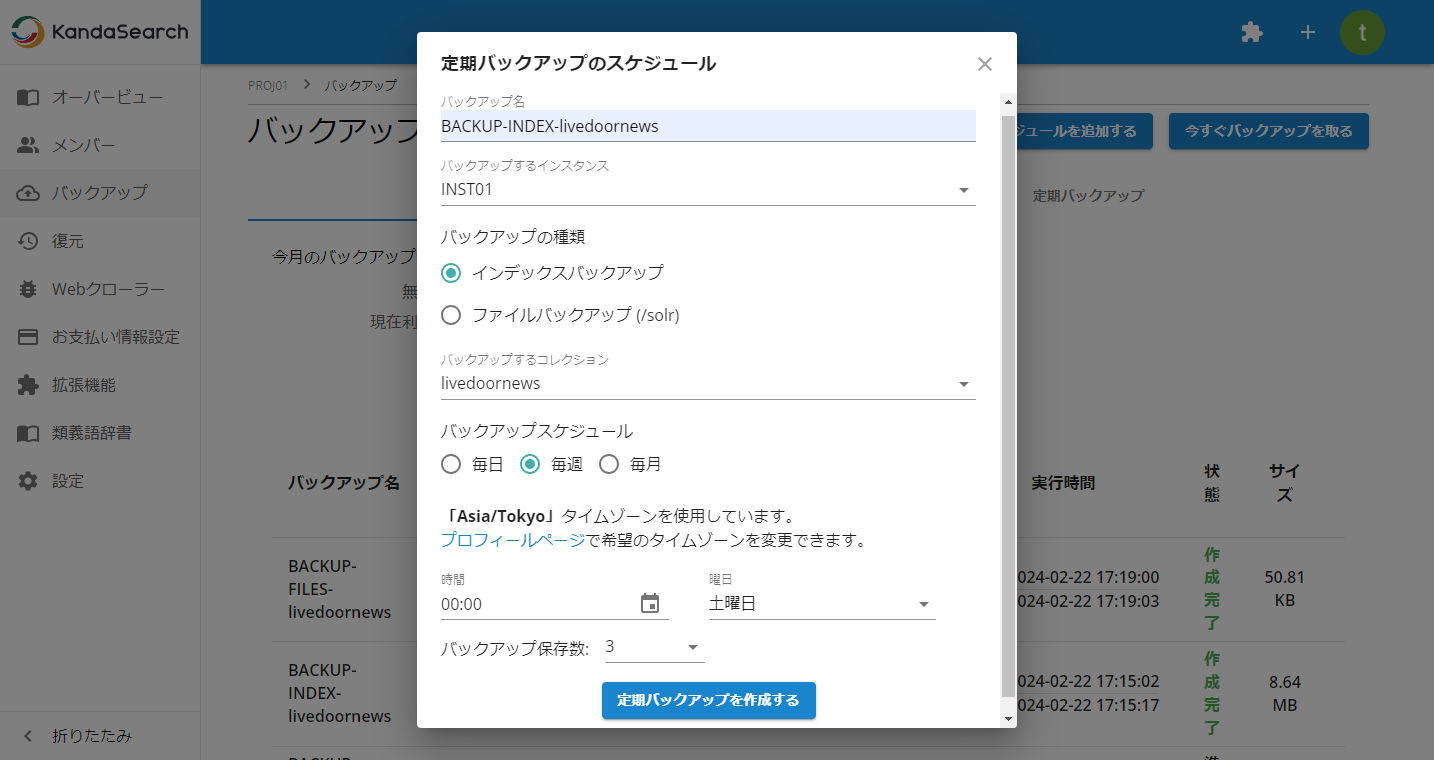
それぞれの指定が完了したら「定期バックアップを作成する」をクリックします。
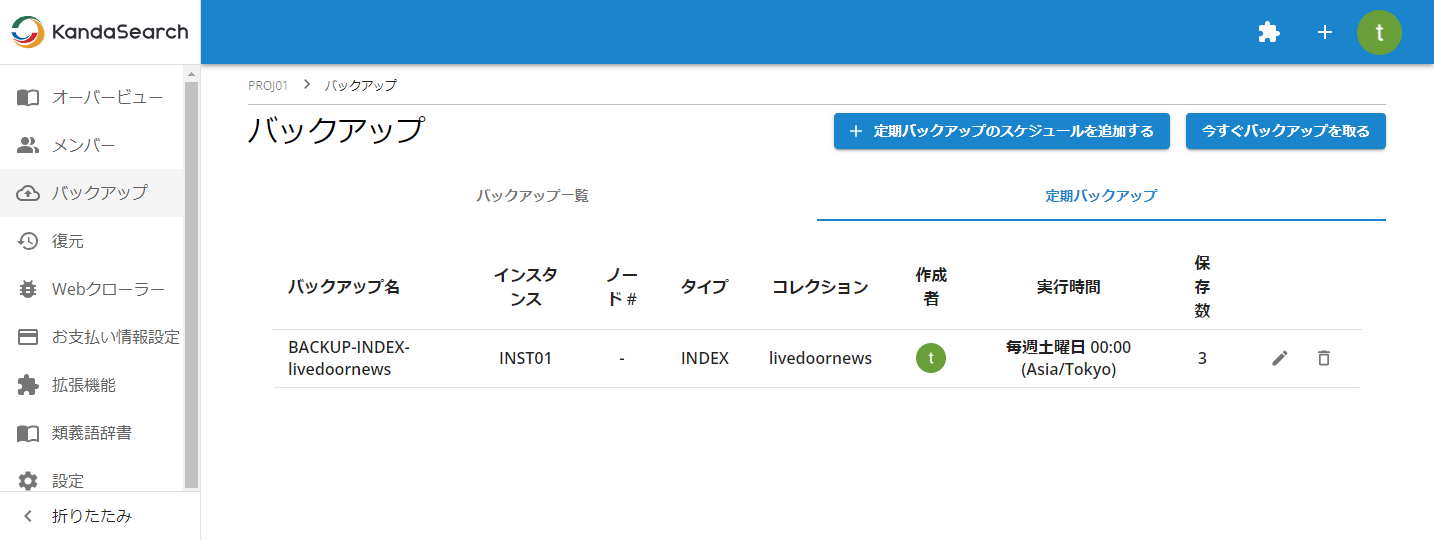
定期バックアップの設定内容は、「定期バックアップ」タブをクリックし、表示された一覧の対象行の編集(鉛筆マーク)アイコンから変更できます。また、削除(ごみ箱マーク)アイコンから削除できます。
重要
有償プランの場合、バックアップに使用するストレージ容量がご利用プランの無償枠を超えた場合は、超えた分が従量課金としてご請求金額に加算されます。
コミュニティプランの場合、無償枠を超えるバックアップは実行できません。
バックアップ消費量は、バックアップ画面を定期的にご覧いただき、ご確認ください。
リストア
次はリストア(復元)についての説明です。
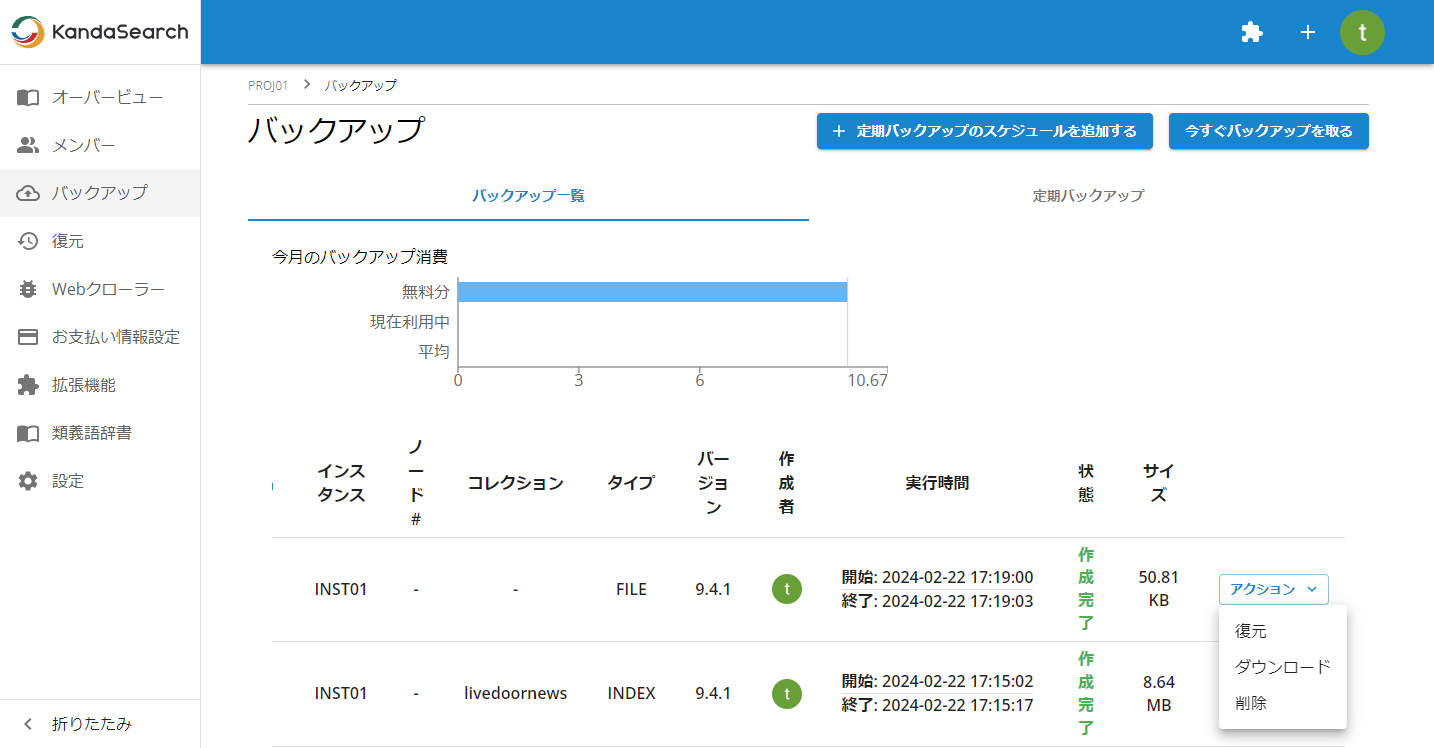
リストアを行う場合は、まず、リストアに使用するバックアップデータをバックアップ一覧から探します。
その行の右端の「アクション」をクリックし「復元」を選択すると、復元の種類別に確認画面が表示されます。 復元先のインスタンスやコレクション(インデックスを復元する場合)を選択後、「復元」をクリックすると、復元が始まります。
復元時は、復元先の指定を間違えないようにご注意ください。
復元の準備作業が開始されると取り消しはできません。
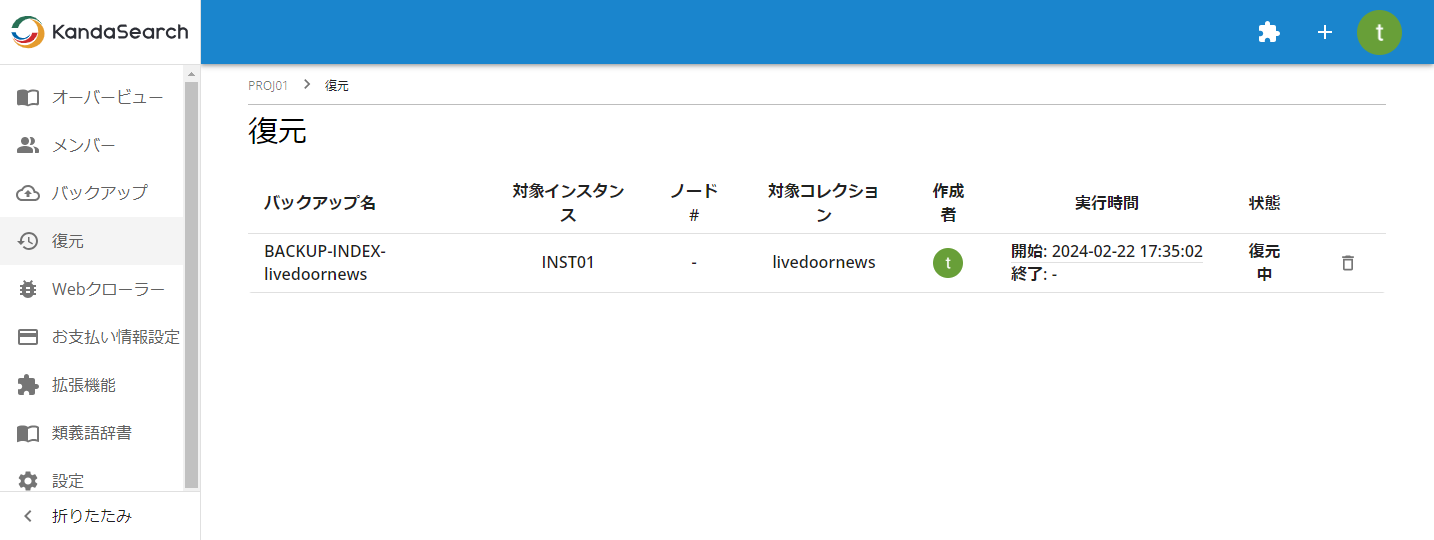
復元作業の状況をいつでも確認できます。
プロジェクトビューの左サイドから「復元」を選択し、状況を確認します。「状態」が「復元完了」と表示されていれば復元が完了しています。
バックアップの削除
不要になったバックアップを削除すると、インスタンスストレージの使用量を削減できます。
バックアップを削除する場合は、「バックアップ」画面のバックアップ一覧から、不要になったバックアップの行の右端の「アクション」をクリックし「削除」を選択します。
重要
検索エンジンインスタンスを削除するとバックアップデータも削除されます。
ヘルスチェック
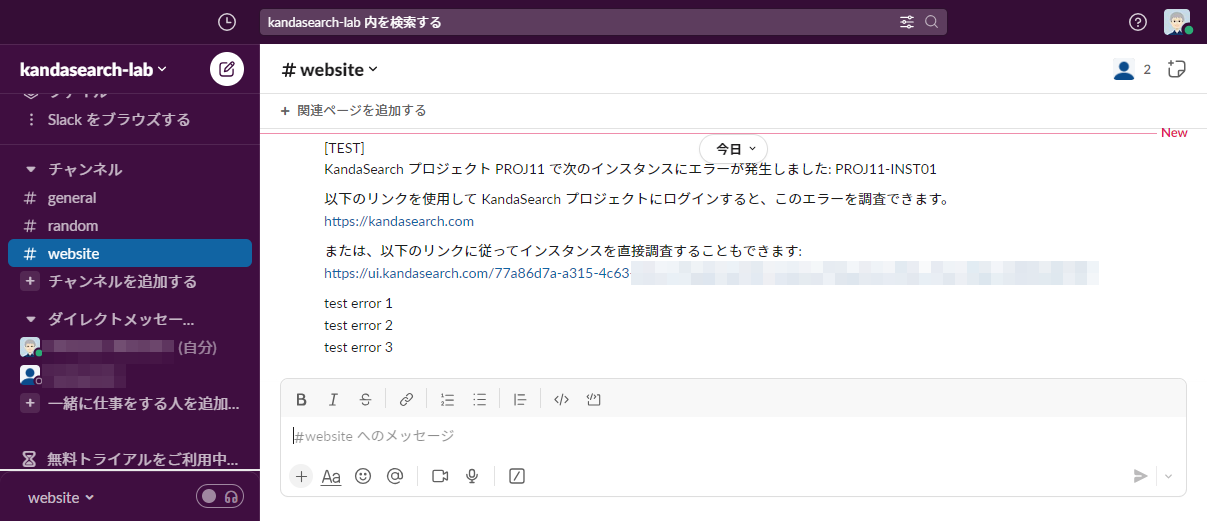
ヘルスチェックでは、検索エンジンのPING機能を使ってインスタンスを監視します。障害が発生した時に、ユーザーが指定した方法で通知を受け取ることができます。
ヘルスチェック機能は、スタンダード以上のプランでご利用可能です。
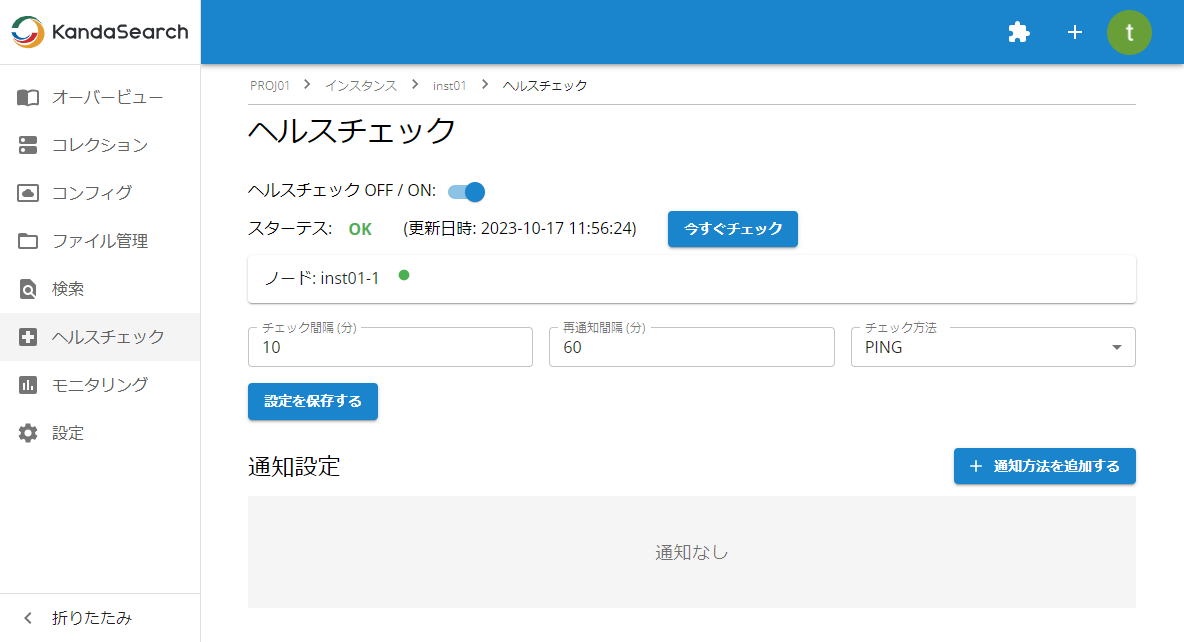
ヘルスチェックのオンとオフ
ヘルスチェックの設定を行うには、インスタンスビューの左サイドから「ヘルスチェック」を選択します。
「監視設定」が定義されていないときは、チェック間隔、再通知間隔、チェック方式を指定後、「設定を保存する」をクリックします。
設定した条件で監視が始まり、「ステータス」欄にステータスと更新日時が表示されます。
「今すぐチェック」をクリックすると直ちにステータスチェックが行われ表示内容が更新されます。
監視を止める場合は、「ヘルスチェック OFF/ON」でスイッチを左側にスライドさせオフにします。
監視条件を変更する場合は、チェック間隔などの各項目を変更後、「設定を保存する」をクリックしてください。
通知設定
続いて、通知設定を行います。
「+ 通知方法を追加する」をクリックします。
通知方式として、「eメール」と「slackなどのWebhook」を利用(両方同時に利用可能)できます。
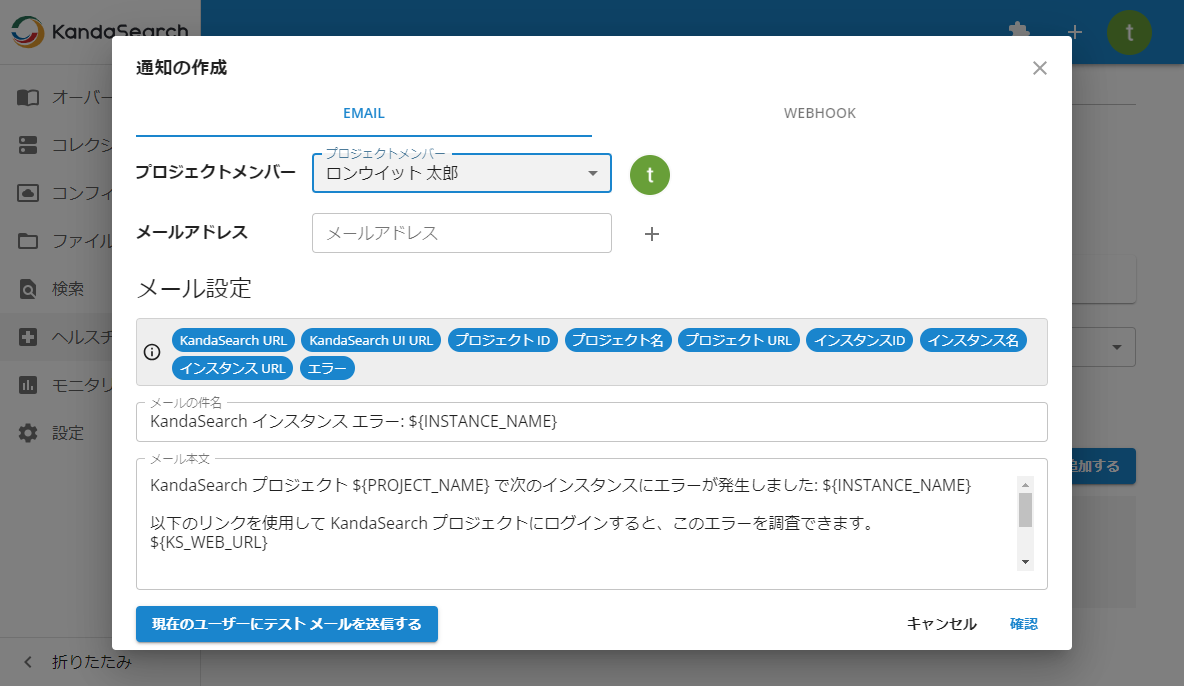
eメールによる通知を行う場合は、「EMAIL」タブにて、プロジェクトメンバーやメールアドレス(eメールアドレスは入力後に「+」アイコンを必ずクリックしてください)、メールの件名、メール本文を指定して、「確認」をクリックします。
件名や本文欄はプレースホルダー式となっていて、任意の位置にアイテムをドラッグ&ドロップすることでカスタマイズができるようになっています。
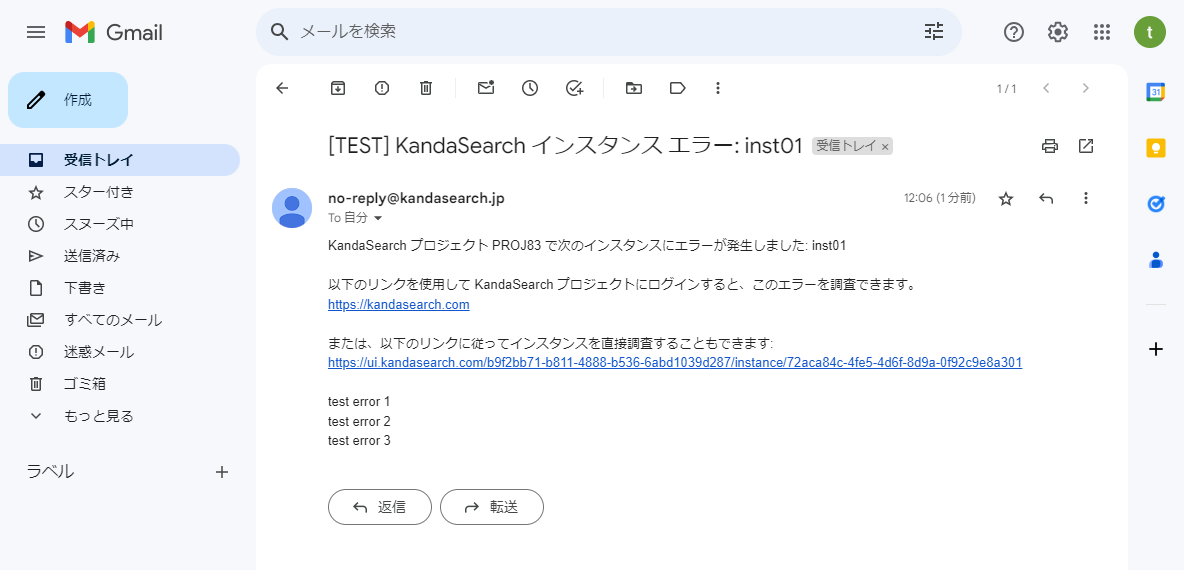
「現在のユーザーにテストメールを送信する」をクリックするとテストメールを送信できます。
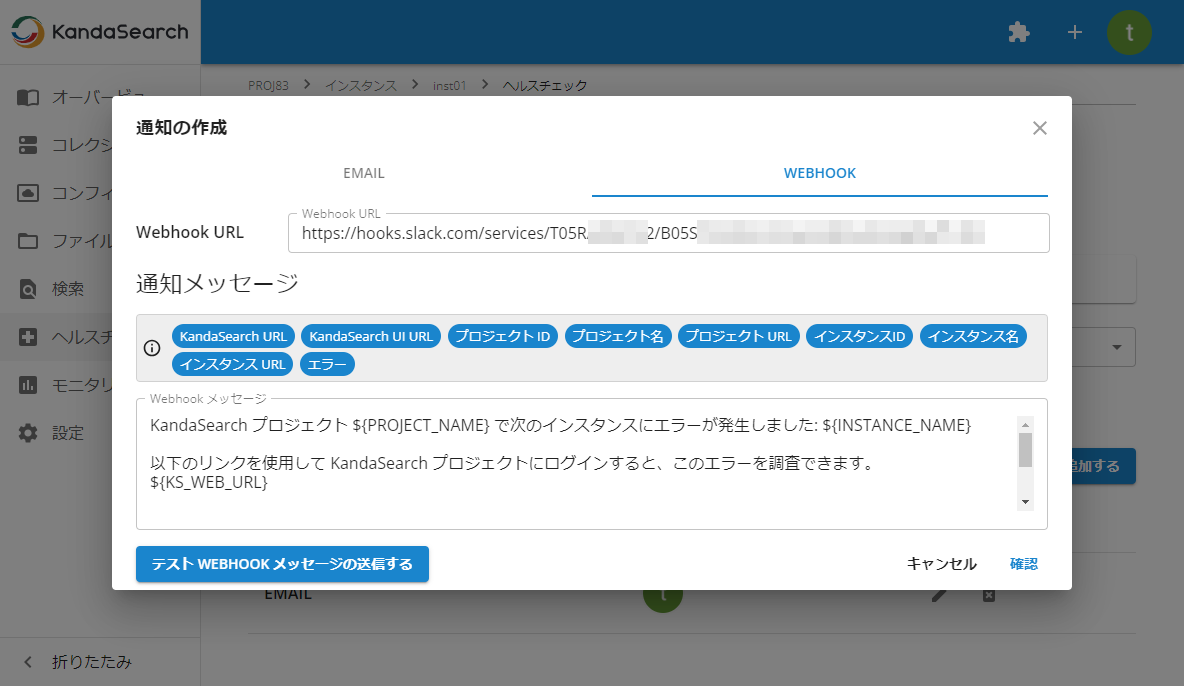
Webhookによる通知を行う場合は、「WEBHOOK」タブにて、Webhook URLを入力後、Webhookメッセージを指定して、「確認」をクリックします。
Webhookメッセージ欄は、eメール方式と同様にプレースホルダー式となっていて、任意の位置にアイテムをドラッグ&ドロップすることでカスタマイズができるようになっています。
「テスト WEBHOOK メッセージを送信する」をクリックするとテストWebhookを送信できます。
通知設定は、各方式で複数の作成が可能です。
通知設定の一覧中の対象行で、編集(鉛筆マーク)アイコンから変更が、削除(ごみ箱マーク)アイコンから削除ができます。
モニタリング
「モニタリング」機能とは、検索エンジンが稼働しているノードのサーバーリソースの使用状況をKandaSearchが一定期間保持することで、KandaSearchの管理画面からそれらのリソース状況をいつでも確認できる機能です。
モニタリングで使用するサーバーリソースの使用状況データの保存は、インスタンスの作成時に自動的に開始されます。
モニタリング機能は、スタンダード以上のプランでご利用可能です。
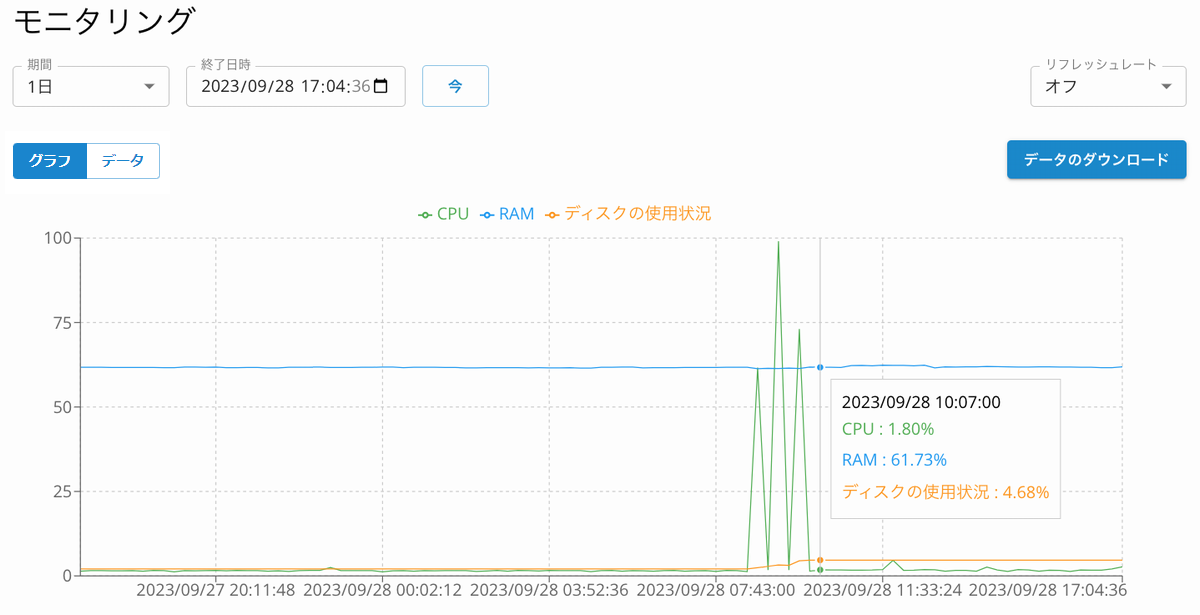
モニタリングを利用するには、インスタンスビューの左サイドメニューから「モニタリング」を選択します。
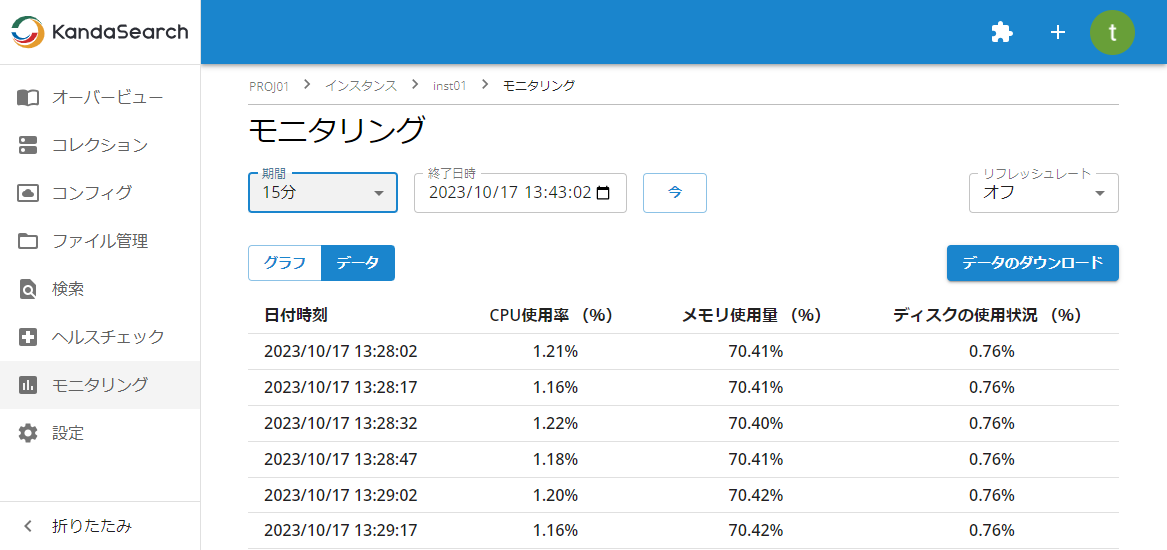
モニタリング対象は、CPU使用率(%)、メモリ使用量(%)、ディスク容量の使用状況(%)、ディスクI/O(%)です。
モニタリング画面内では、以下の指定が可能です。
- 表示データの「期間」「終了日時」を指定できます。例えば、「終了日時」に「2023/10/13 15:00」、「期間」に「1時間」を指定すると、2023/10/13 14:00から2023/10/13 15:00までの15秒間隔のデータが表示されます。
- 表示形式は「グラフ」、「データ」のいずれかを指定できます。各表示形式のボタンをクリックして指定してください。
- 「リフレッシュレート」で間隔時間を指定すると、指定間隔で表示が自動更新されます。
- 「データのダウンロード」をクリックすると、表示データのダウンロードができます。
- グラフ上部の「CPU」「RAM」「ディスクの使用状況」「RootディスクI/O」「SolrディスクI/O」をクリックすると、グラフ内の当該ラインの非表示/表示をコントロールできます。
ウイルスチェック
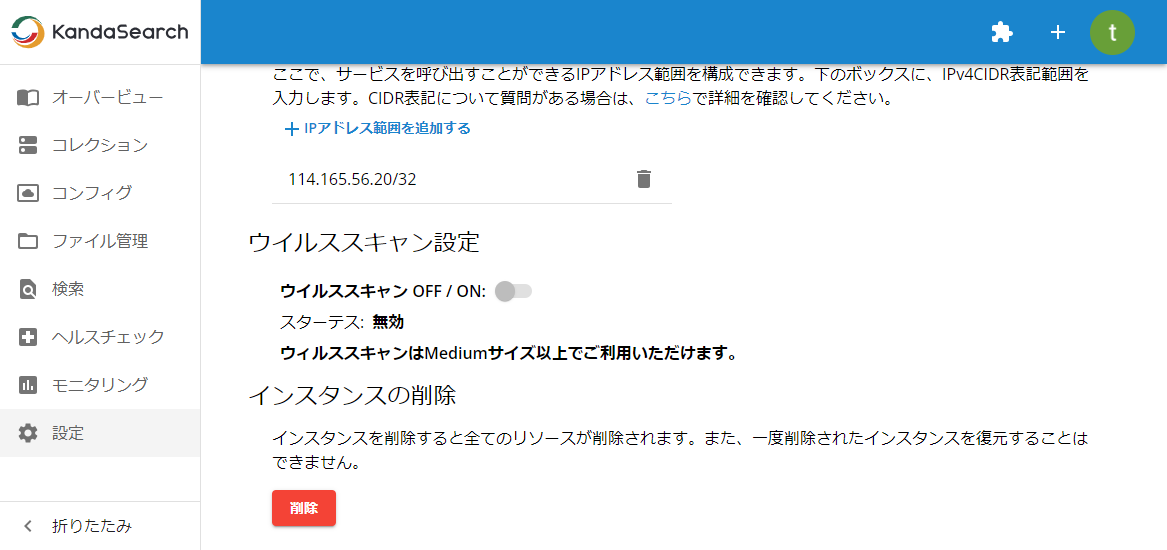
KandaSearchは、インスタンスのSolrディレクトリ配下のファイルに対しウイルスチェックを行い、ウイルスを駆除する機能を有しています。 ウイルスチェック機能は、スタンダードのプロ以上のプランでご利用可能です。
ウイルスチェックを有効にするには、インスタンスビューの左サイドの「設定」において「ウイルススキャン」をオンにします。
ウイルスチェックを実施することで、より安全にKandaSearchをご利用いただけます。
昨今では、企業が求めるITセキュリティのレベルが上がり、あらゆるサーバー上のセキュリティ対策の実施を要件とするシステム開発も多く見られるようになりました。そのような仕様に合致させる必要がある場合には、このウイルスチェック機能のご利用をご検討ください。
IPアドレス許可設定
インターネット側からKandaSearchのインスタンスにアクセスするには、接続元サーバー、パソコンなどのIPアドレスを、事前に登録しておく必要があります。
これにより、検索エンジンへの第三者からのアクセスをブロックし、安心してKandaSearchをご利用いただけるようになっています。
IPアドレスの許可設定を行うには、インスタンスビューの左サイドの「設定」を選択します。
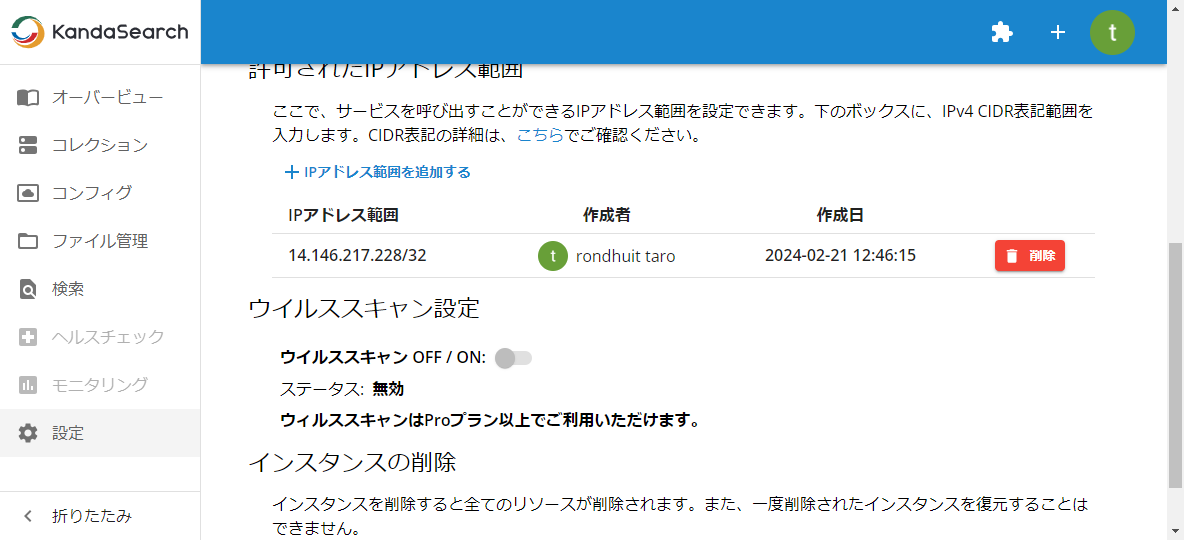
「許可されたIPアドレス範囲」の「+ IPアドレス範囲を追加する」をクリックし、IPアドレスを登録します。 IPアドレスはIPv4のCIDR表記で指定します。
なお、登録可能な範囲セットは料金プランにより異なります。
登録が完了すると、登録したIPアドレス範囲とともに作成者と作成日時が表示されます。作成者と作成日時が表示されることで、各レコードの要・不要の判断がしやすくなっています。
登録が完了したら、パソコンの場合は、ブラウザからSolr Admin URLにアクセスできることを確認します。
サーバーの場合は、curlコマンドを使って検索APIなどを実行し正常レスポンスが返ってくることを確認します。数分経過後も ”302 Found” が返ってくる場合は、登録済みのIPアドレスが違っている可能性があります。
スタンドアロンとSolrCloud
1つの検索システムについて、スタンドアロン構成では、検索エンジンがサーバーマシン1台から構成されているのに対し、SolrCloud構成では複数台のサーバーから構成されます。
SolrCloudの使い方として、例えば4台のノード(サーバー)が利用できるときに、インデックスを4つのシャード(Shard:1つのインデックスを担当するSorコアのこと)に分けることが考えられます。そうすることで検索処理による1ノードごとのサーバーの負荷を小さくし、検索速度を向上させることができます。
さらに、サーバー間でインデックスを多重化すれば高可用性を実現できます。サーバーが1台ダウンしたときにも検索システム全体における正常動作を保ったり、サーバーを1台止めてメンテナンスを行ったりすることが可能になるのです。
企業で検索エンジンを導入する場合は、このSolrCloud構成が採用されることが多いです。
KandaSearchでSolrCloudのご利用をご検討の場合は、お問い合わせフォームよりお問い合わせください。