

目次
イントロダクション
先月、私は第47回国際ACM SIGIR情報検索の研究と開発に関する会議に参加しました。今年は、2024年7月14日から18日まで、アメリカのワシントンD.C.で開催されました。このフォーラムでは、情報検索(IR)における最新の研究成果や技術が発表されます。会議は5日間にわたり、論文発表、システムデモンストレーション、ポスター、博士課程のコンソーシアム、チュートリアル、およびワークショップが行われました。今年のSIGIRには、伝統的なセッションに加えて、産業トラック(SIRIP)、政府デー、大規模言語モデル(LLM)デー、その他の特別イベントが含まれていました。
 |
|---|
| イベント会場はキャピタルヒルトンホテルでした。 |
RONDHUITの代表として、同僚のソラ・ララ(Lara Solà)と一緒にこのイベントに参加したことは、内容と性質の観点から特に意義深いものでした。また、私はしばらくの間、母国に滞在していたため、同僚に直接会うのは久しぶりでした!
会議中、私は1日の間にいくつもの発表を聞いており、全ての発表の感想はとても書ききれないので、以下は興味深いと感じた発表のみ抜粋してレポートしたいと思います。
日曜日: チュートリアル
初日はチュートリアルに充てられ、さまざまなテーマに関する深い掘り下げが行われました。私が参加したチュートリアルは次の通りです。
- 情報検索のための大規模言語モデルによるエージェント(Large Language Model Powered Agents for Information Retrieval): このチュートリアルでは、LLMがIRタスクをどのように強化できるかについて、基本から高度な技術までを網羅した詳細な説明が行われました。
- 大規模言語モデルの強化: 実世界でのインタラクションのためのツール学習(Empowering Large Language Models: Tool Learning for Real-World Interaction): LLMを実世界のアプリケーションに活用する方法に焦点を当て、このセッションでは実際の実装と課題について強調されました。
- 堅牢な情報検索(Robust Information Retrieval): 多様で予測不可能なデータを扱うための、IRシステムにおける堅牢性を確保するための方法が議論されました。
このようなセッションが「チュートリアル」と呼ばれていたにもかかわらず、今回はハンズオン(実務的な内容)の経験がなく、少し奇妙に感じました。
 |
|---|
| 初日はチュートリアルに充てられました |
月曜日: 初日
会議の正式な初日は、複数のセッションが行われました。私が参加したセッションの概要を以下に示します。
セッション 1: 評価
情報検索における評価は、検索アルゴリズムやシステムの有効性と効率性を評価するために不可欠です。このセッションでは、評価に関するさまざまな側面が、理論的および実践的な観点から取り上げられました。ある論文では、IRランキングにおける同点処理の課題が掘り下げられ、精度を向上させるための方法が提案されました。また、統計的有意性を文脈に合わせて検討することの重要性が強調され、誤解を招く結論を避けるための手法が示されました。さらに、推薦システムにおける公平性評価の信頼性が検討され、公平性と関連性の相互作用が強調されました。最後に、大規模検索システムにおける評価指標の重要な要素についての議論が行われ、意味のある評価がどのように構成されるべきかについての洞察が提供されました。これらの論文は、IRシステムが効果的かつ公平であることを確保するために、評価方法論の理解を深めるための貴重な貢献をしています。
セッション 2: 多言語検索
グローバルなコミュニケーションが拡大し、言語を越えた検索能力の需要が増加する中で、多言語検索の重要性が増しています。このセッションでは、複数の言語にわたる検索を強化するための革新的な技術が探求されました。ある研究では、密なパッセージ検索を改善するための高度なネガティブサンプリング技術に焦点を当て、多言語環境での検索プロセスの最適化が行われました。また、メタ蒸留を使用して多言語データを整列させる方法が紹介され、より正確で効果的なセマンティック検索が可能になりました。これらの進展は、RONDHUITと我々の製品であるKandaSearchにとって特に関連性が高く、多様でグローバルなユーザーベースのニーズに応えるために、堅牢な多言語検索機能を開発する重要性を強調しています。
セッション 3: レコメンダシステムとソーシャルメディア
このセッションでは、レコメンダシステムがソーシャルメディアでどのように活用され、ユーザーの行動や好みがどのようにモデル化され、利用されるかに焦点が当てられました。ある論文では、LLMを用いたユーザーシミュレーション技術を使用して、実稼働のレコメンダシステムにおけるライブ実験を最小限に抑える方法が探求されました。また、ソーシャルメディアの推薦における行動埋め込みの進化が、特にSnapchatのようなプラットフォームに焦点を当てて検討されました。さらに、Amazon Musicにおける検索スペル修正技術の分析が行われ、正確な修正がユーザー体験をどのように向上させるかが示されました。
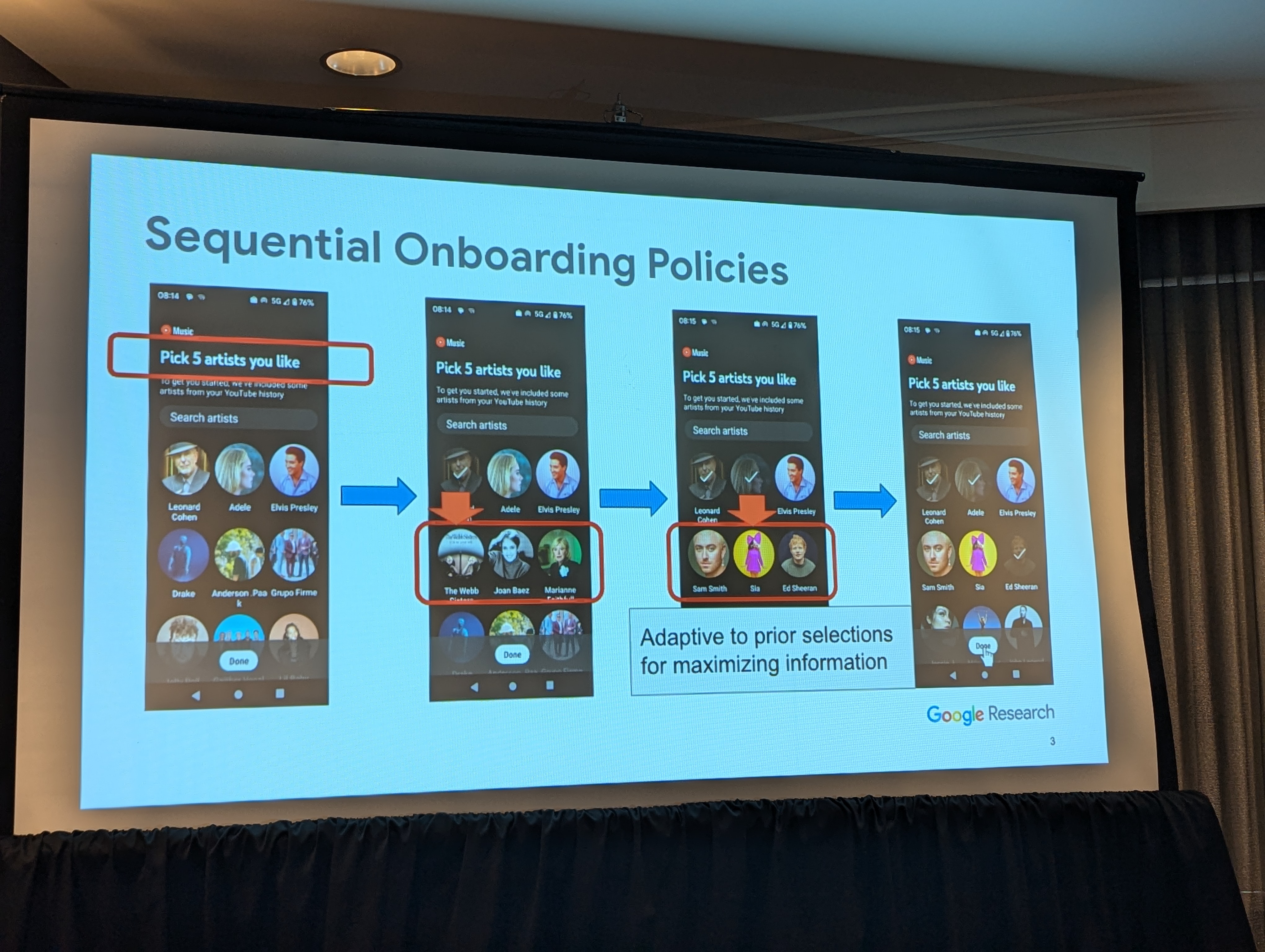 |
|---|
| レコメンダーシステムにおけるライブ実験の最小化: ユーザーシミュレーションを使用した嗜好引き出し方針の評価(Minimizing Live Experiments in Recommender Systems: User Simulation to Evaluate Preference Elicitation Policies)に関するスライド |
火曜日: LLMデー
LLMデーでは、GPT-4やLLaMAのような大規模言語モデルが検索およびレコメンデーションシステムにおいてどのように革命的な役割を果たしているかに焦点が当てられました。この日のセッションでは、LLMの研究進展、オープンソースの開発、およびIRとの統合が取り上げられ、推論効率、合成データ生成、長文コンテキストの理解、AI倫理などの重要なトピックが議論されました。この日を通じて、LLMがこれらの技術の未来をどのように再構築しているかについて、専門家の間での協力と知識交換が奨励されました。
お気に入りの論文: 高密度情報検索のための次元重要性推定
SIGIR 2024で特に印象に
残った論文の1つは、「高密度情報検索のための次元重要性推定」に関するものでした。この研究は、情報検索において高次元の埋め込みを扱う際の課題に焦点を当てています。この論文の著者は、これらの高次元表現をクエリに依存したサブスペースに投影することで、検索の有効性を大幅に向上させることができると仮定しています。彼らは、次元重要性推定器(DIME)と呼ばれる新しいアプローチを導入し、各クエリに最も関連性の高い次元を識別して選択することで、検索結果の質を向上させます。
この研究は、Principal Component Analysis(PCA)がデータの次元を削減し、最も重要な情報を保持するのと同様に、高密度検索システムを最適化する方法を提供するため、特に重要です。さらに、この技術は、クラシカルな検索におけるストップワード除去の役割と比較することができます。ストップワードが除去されることで検索の精度が向上するように、DIMEは表現空間の次元を選択的に削減し、検索性能を向上させます。この論文は、特定のシナリオにおいて最大58.6%の性能向上を実現できることを示しており、情報検索分野における重要な進歩を意味します。論文はこちらからご覧いただけます。
水曜日: 政府デーとSIRIP
政府デー
政府デーでは、政府がAIを活用して公共の利益を促進し、人々の生活の質を向上させるサービスをどのように強化しているかに焦点が当てられました。情報検索(IR)コミュニティは、正確で根拠に基づいた結果を提供するAIツールを開発することで、これらの取り組みを支援するために特に重要な役割を果たしています。私の主な関心は研究にありますが、政策に関する議論にはあまり惹かれないものの、IRがAI技術を通じて公共政策と社会的影響を形作る上で果たす重要な役割を認識しています。
SIRIPパネルディスカッション
SIRIP(SIGIR Symposium on IR in Practice)では、学術界と産業界のギャップを埋めることに焦点を当て、IR技術が実際のシナリオでどのように適用されているかが紹介されました。このパネルディスカッションでは、業界リーダーと学術専門家が参加し、埋め込みの時代における検索エンジンの未来について議論が行われました。この議論は、検索エンジンが完全に埋め込みベースの方法に移行するかどうか、その移行に伴う課題に焦点を当てていました。
主な洞察としては、エンジニアリングと科学的イノベーションのバランス、巨大なデータセットに対する埋め込みの使用に伴う計算の複雑さ、そして従来の方法と埋め込みを組み合わせたハイブリッド検索アプローチの必要性が挙げられました。また、パネルリストは、多言語対応を維持し、新しい語彙に対処しながら、埋め込みが複雑な意味を捉える際の限界に対処するための実際の課題にも言及しました。
重要な見解
私にとっての主な見解は、埋め込みが情報検索において強力なツールである一方で、普遍的な解決策ではないという点です。たとえば、書籍検索のような特定のユースケースでは、ユーザーがISBNのような正確な識別子を使用して検索することがよくあるため、埋め込みにのみ依存するのは現実的ではありません。こうした識別子は、シンプルなデータベース検索で効率的に検索することができます。この議論はまた、データの数値表現に焦点を当てるのではなく、ユーザーの意図を理解し、それを満たすことが重要であることを強調しました。情報検索において言語は単なる記述ではなく、行動を促すためのものです。
ポスターセッションもこの日に開催されました。
会議内容に関する最終的な感想
SIGIR 2024を通じて、大規模言語モデル(LLM)が情報検索(IR)分野およびその他の分野でどれほど変革的な役割を果たしているかが明らかになりました。LLMはさまざまな分野で広く採用されており、私たちの問題解決のアプローチを大きく変えています。IR分野では、LLMがセマンティック検索におけるモデル選択のために重要であり、より正確で文脈に合わせた情報検索が可能になっています。また、LLMはユーザー行動のシミュレーションにも使用されており、レコメンダシステムにおけるコールドスタート問題に対処するのに役立っています。
さらに、LLMはユーザーの好みを定義し、システムがより精密に関連性やラベリングを割り当てるための重要な役割を果たしています。また、LLMはデータプルーニングにもますます利用されており、データセットを精緻化してモデルのトレーニング効率を向上させています。クエリ補正の分野でも、LLMは再現率と精度を向上させ、ユーザーがより正確で関連性の高い検索結果を得ることができるようにしています。
しかし、LLMの多用途性と有効性にもかかわらず、LLMには大きな課題が伴います。それらは計算リソースを大量に消費し、トレーニングとデプロイの両方に多大なリソースを必要とします。これによりコストが上昇するだけでなく、こうした強力なモデルのアクセス可能性や持続可能性についても懸念が生じます。LLMの使用が拡大する中で、パフォーマンスと実用性のバランスを取る解決策を模索することが重要です。
イベントの運営に関する最終的な感想
SIGIR 2024は多くの貴重な洞察を提供しましたが、運営面で改善の余地がある点もいくつかありました。たとえば、チュートリアルデーは期待に応えるものではありませんでした。多くの参加者が期待していたハンズオンセッションの代わりに、ほとんどが講義形式で行われました。この実践的な取り組みが欠けていたため、チュートリアルは拡張されたプレゼンテーションのように感じられ、インタラクティブな学習体験とは言い難いものでした。これが過去にも同様だったのかどうかはわかりません。
また、プレゼンテーション自体の質にも改善の余地がありました。特にデザイン面で、多くのスライドは論文から直接スクリーンショットを取ったものであり、テキストが密集している一方で視覚的な補助が最小限でした。このアプローチでは、セッションが静的に感じられ、複雑なアイデアを効果的に伝えるために必要な示威的要素が欠けていることが多かったです。
ネットワーキングやコミュニティ構築を促進するために設計されたソーシャルイベントは、やや期待外れでした。新参者として、もう少し歓迎されていると感じたかったですし、ラテン系として、DEI(ダイバーシティ、エクイティ、インクルージョン)イベントに関する情報がもっとアクセスしやすければ良かったと感じました。
これらの短所にもかかわらず、会議は依然として貴重な洞察とネットワーキングの機会を提供しました。来年のヨーロッパでのイベントでは、より良い運営とより魅力的なセッションを期待しています。
 |
|---|
| また来年! |