
TUTORIAL
03. Basics of Inverted Index
On this page
- Full-text search retrieval method
- Inverted index
- Search
- Score calculation
- The method for dividing Japanese words
"Full-text search" refers to the ability to search the entire document, as opposed to "simple search" where only parts of the document, such as IDs, are targeted. Here, we'll discuss the "inverted index" that search engines use to achieve fast full-text search, keyword search using it, and the basics of scoring to determine search result order.
If you are already familiar with full-text search based on the inverted index method, you can skip this chapter.
Full-text search retrieval method
There are two main search methods for full-text search: sequential search and inverted index search methods.
Sequential search method is a method where the specified string and the document being searched are compared sequentially from the beginning during the search. This is similar to the Linux 'grep' command or the 'like' search in a Relational Database (RDB).
On the other hand, the inverted index method adopted by search engines is a method where an index is created in advance from the documents being searched. It labels the documents and creates an index so that documents can be retrieved using these labels.
Generally, there are the following differences between RDBs and search engines.
| RDB(Relational Database) | Search Engine | |
|---|---|---|
| Features | Relational model, Transaction management, CRUD | High-speed full-text search |
| Tables | Multiple, Normalization | Single, Denormalization |
| Search | SELECT, Relational algebra | Keyword search (AND/OR/NOT, variant spellings, synonyms, ...), Semantic search (KandaSearch) |
| Search Results | Set, Sort | Relevance order (based on query and document similarity) |
As indicated in the table above, KandaSearch can handle semantic search, but from here on, we will only explain 'keyword search'.
Inverted index
Inverted indexes are generally created with the following steps.
As an example, we will create an inverted index for the following three documents.
Document ID Document text
1 カツオはサザエの弟
2 サザエはワカメの姉
3 ワカメはカツオの妹
Step-1
First, we split the document text into words and group them into pairs of word and document ID.
カツオ:1, は:1, サザエ:1, の:1, 弟:1,
サザエ:2, は:2, ワカメ:2, の:2, 姉:2,
ワカメ:3, は:3, カツオ:3, の:3, 妹:3
Step-2
We sort by words, group the document IDs for the same word as shown in the diagram below, and create a list. This completes the creation of the inverted index.
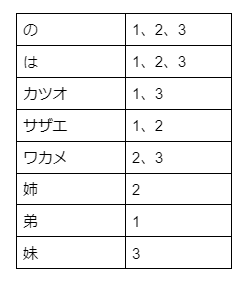
In the following, we will simply refer to the 'inverted index' as 'index'.
Search
We will now perform a search using the index.
EXAMPLE-1
Let's assume we have the following documents.
Document ID Document text
1 カツオはサザエの弟
2 サザエはワカメの姉
3 ワカメはカツオの妹
Now, let's assume we have a search engine that has created and stored an index like the one in the diagram below.
We perform a search query for 'サザエ'. (q=サザエ)
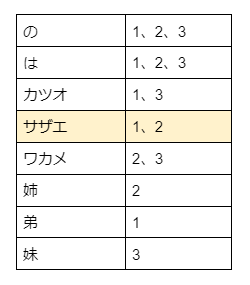
The search engine returns documents with IDs 1 and 2 as the result.
Results.
カツオはサザエの弟 Document ID=1
サザエはワカメの姉 Document ID=2
Let's try changing the query and perform the search.
EXAMPLE-2
Let's assume we have the following documents.
Document ID Document text
1 カツオはサザエの弟
2 サザエはワカメの姉
3 ワカメはカツオの妹
Now, let's assume we have a search engine that has created and stored an index like the one in the diagram below.
We perform a search query for 'ワカメ AND 姉'. (q=ワカメ AND 姉)
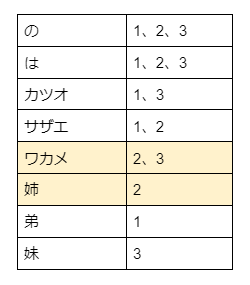
Documents containing 'ワカメ' have IDs 2 and 3, and '姉' is in document ID 2. Since the search is for 'AND' between them, the search engine returns the document with ID 2 as the result.
Results.
サザエはワカメの姉 Document ID=2
Let's further modify the query and perform the search.
EXAMPLE-3
Let's assume we have the following documents.
Document ID Document text
1 カツオはサザエの弟
2 サザエはワカメの姉
3 ワカメはカツオの妹
Now, let's assume we have a search engine that has created and stored an index like the one in the diagram below.
We perform a search query for 'ワカメ OR 妹'. (q=ワカメ OR 妹)
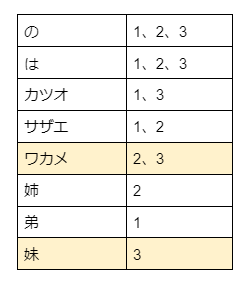
The document IDs containing 'ワカメ' are 2 and 3, and the document ID containing '妹' is 3. Since this is an 'OR' search, the search engine will return documents with IDs 2 and 3. However, the results will be ordered with document ID 3 first, followed by document ID 2.
Results.
ワカメはカツオの妹 Document ID=3
サザエはワカメの姉 Document ID=2
This is one of the differences between a full-text search engine and an RDB in that the search engine can return search results in a user-preferred order. This display order is determined by calculating a 'score'.
Score calculation
A 'score' is a function representing the relevance between the query (q) and the search target document (d), where a higher numerical value indicates a higher relevance between the two.
Here, we will consider using 'cosine similarity' for calculating the score.
score( q, d ) = cos( q, d )
Cosine similarity is an algorithm that considers two vectors to be more similar if the angle between them is small. A vector consists of 'direction' and 'magnitude', and the number of dimensions in the vector space is equal to the vocabulary size in the index. However, for simplicity in the following explanation, we will consider the number of words used in the query as the number of dimensions.
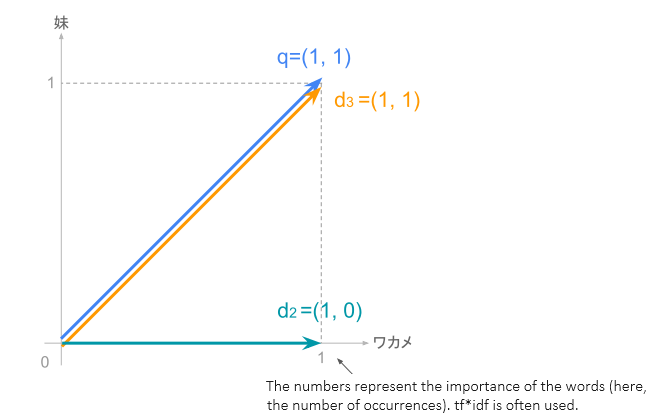
As seen from this diagram, the angle between the query and the vector for d3 is 0 degrees, so cos(q,d3)=cos(0)=1.
On the other hand, the angle between the query and the vector for d2 is 45 degrees, so cos(q,d2)=cos(45)=0.525...
Since the score for document 3 is 1 and the score for document 2 is 0.525, we can conclude that document 3 has a higher relevance to the search terms than document 2.
The TF*IDF in the diagram represents a function that indicates the importance of words. It allows us to quantify the importance of words in a query or document based on the 'term frequency (TF)' in the document and the 'inverse document frequency (IDF)' of the word, which is the reciprocal of the number of documents in which the word appears.
As explained above, for search engines to create an index or calculate scores, they need to handle text at the word level. Documents in languages like English are separated by spaces, making word boundaries clear. However, in Japanese text, word boundaries are not always clear.
For example, when considering the document 'ここではきものを脱ぐ', the boundaries of the words can be thought of as follows:
ここ / では / きもの / を / 脱ぐ
ここ / で / はきもの / を / 脱ぐ
きもの:clothing
はきもの:shoes
As shown above, the meaning of a word can change depending on where it is split.
In handling Japanese documents with such challenges, what methods are suitable for dividing words?
The method for dividing Japanese words
There are two major methods for dividing Japanese words, each with its own advantages and disadvantages.
1 - Morphological analysis
- Dictionary-based word segmentation.
- The search results have low search errors, but are prone to search omissions.
- Timely updates to the dictionary are necessary.
Example of segmentation.
緊急事態宣言 → 緊急 / 事態 / 宣言
2 - N-gram
- Mechanically split into N-character units. 2-grams, 3-grams, and so on.
- The search results have low search omissions, but are prone to search errors.
- There is a tendency for the index size to become large.
Example of segmentation. (When N=2)
緊急事態宣言 → 緊急 / 急事 / 事態 / 態宣 / 宣言
The search engine provided by KandaSearch allows the use of both options, enabling users to switch between or combine them according to business requirements, effectively accommodating the complexities of Japanese language search.